
CM3leon represents a significant leap forward in the field of generative AI, offering a more efficient and versatile approach to both text-to-image and image-to-text generation. This state-of-the-art model is designed to handle a wide range of tasks with remarkable efficiency, making it a valuable tool for researchers, developers, and creatives alike.
One of the key features of CM3leon is its ability to perform both text-to-image and image-to-text generation within a single model. This dual capability is achieved through a unique training recipe that includes a large-scale retrieval-augmented pre-training stage followed by a multitask supervised fine-tuning stage. This approach not only simplifies the training process but also results in a model that is both powerful and efficient.
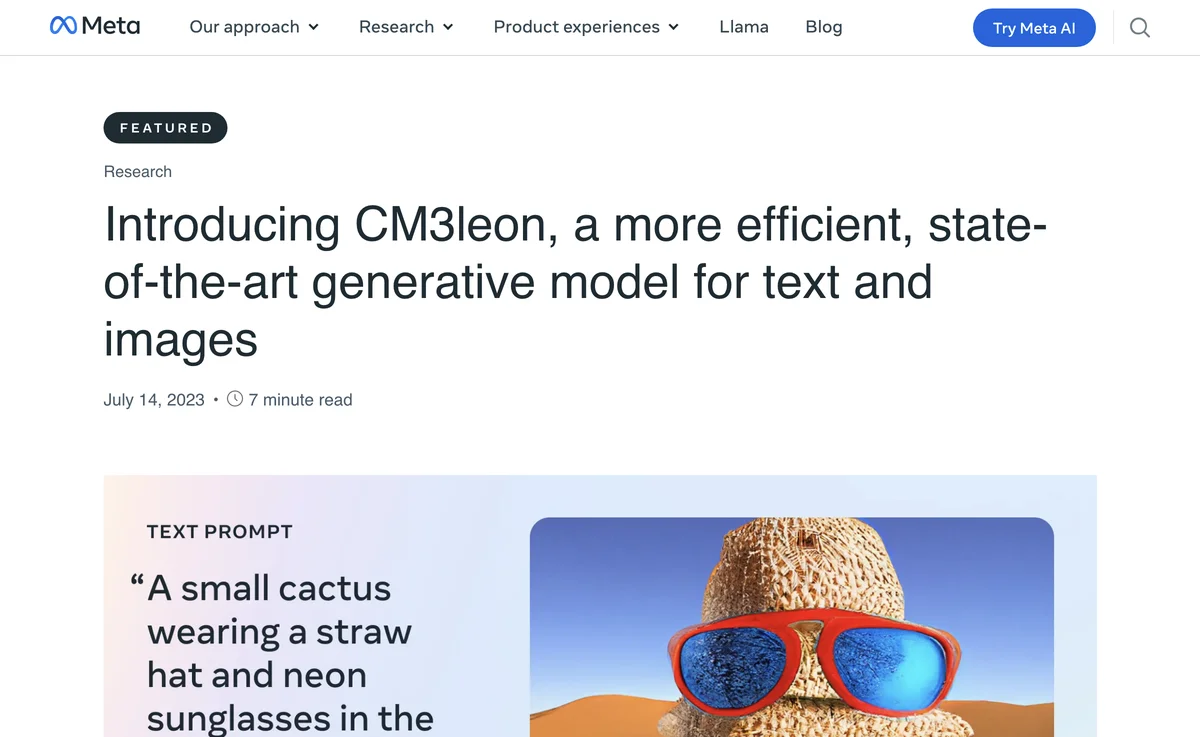
CM3leon's performance is particularly noteworthy in the area of text-to-image generation, where it achieves state-of-the-art results with significantly less computational resources than previous models. This efficiency does not come at the cost of quality; CM3leon is capable of generating highly detailed and coherent images that closely follow the input prompts. This makes it an ideal tool for applications ranging from digital art creation to content generation for media and entertainment.
In addition to its text-to-image capabilities, CM3leon also excels in image-to-text tasks such as image captioning and visual question answering. The model's ability to understand and generate text based on visual content opens up new possibilities for applications in accessibility, education, and beyond.
CM3leon's versatility is further enhanced by its ability to perform text-guided image editing. This feature allows users to modify images based on textual instructions, such as changing the color of the sky or adding specific elements to a scene. This capability is particularly useful for graphic designers and content creators who need to make quick adjustments to visual content.
The model's architecture is based on a decoder-only transformer, similar to those used in text-based models. However, CM3leon's ability to input and generate both text and images sets it apart from its predecessors. This multimodal approach enables the model to handle a variety of tasks with a single architecture, reducing the need for multiple specialized models.
Training CM3leon involved a retrieval-augmented process that improved the model's efficiency and controllability. The model was then fine-tuned on a wide range of image and text generation tasks, further enhancing its performance across different applications.
As the AI industry continues to evolve, models like CM3leon are paving the way for more sophisticated and versatile generative AI tools. By combining efficiency, versatility, and state-of-the-art performance, CM3leon is setting a new standard for what is possible in the field of generative AI.