
More Efficient NLP Model Pre-training with ELECTRA
Introduction
In the rapidly evolving field of Natural Language Processing (NLP), pre-training models have become a cornerstone for achieving state-of-the-art results. Among these, ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) stands out as a novel approach that not only matches the performance of existing models like RoBERTa and XLNet but does so with significantly less computational resources.
The Evolution of NLP Pre-training
Recent advancements in language pre-training have led to the development of various models such as BERT, RoBERTa, and T5. These models leverage large amounts of unlabeled text to build a general understanding of language before fine-tuning on specific tasks. However, traditional methods can be inefficient, particularly in how they utilize computational resources.
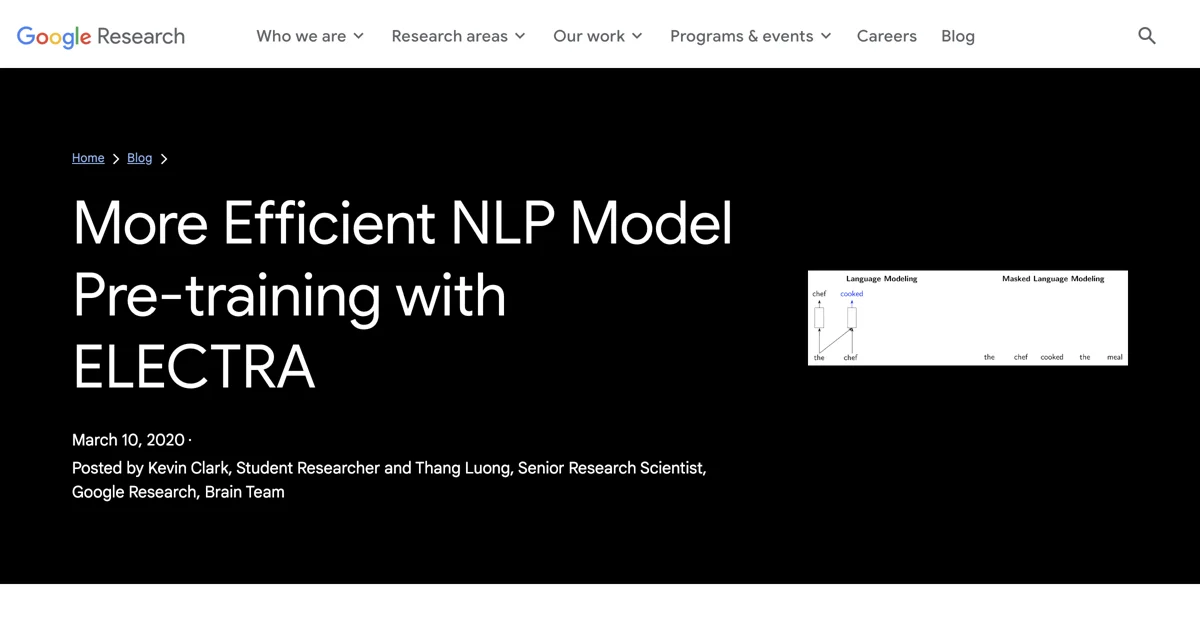
Language Models vs. Masked Language Models
Existing pre-training methods generally fall into two categories:
- Language Models (LMs): These models, like GPT, process text in a left-to-right manner, predicting the next word based on previous context.
- Masked Language Models (MLMs): Models such as BERT and RoBERTa predict the identities of masked words in the input, allowing them to utilize context from both sides of the token being predicted.
While MLMs are bidirectional, they only predict a small subset of words, which can limit the amount of information learned from each sentence.
Introducing ELECTRA
ELECTRA takes a different approach by introducing a new pre-training task called Replaced Token Detection (RTD). This method trains a bidirectional model while learning from all input positions, akin to LMs, but with greater efficiency.
How ELECTRA Works
Inspired by generative adversarial networks (GANs), ELECTRA trains the model to distinguish between "real" and "fake" input data. Instead of masking tokens, ELECTRA replaces some tokens with plausible alternatives. For instance, the word "cooked" might be replaced with "ate". The model's task is to identify which tokens have been replaced, allowing it to learn from every input token rather than just a small subset.
Efficiency and Performance
ELECTRA has demonstrated remarkable efficiency, achieving performance comparable to RoBERTa and XLNet while using less than 25% of the compute. In fact, it can be trained on a single GPU in just a few days, outperforming models that require significantly more computational power.
Results and Comparisons
In extensive evaluations, ELECTRA has shown to outperform other state-of-the-art models on benchmarks like GLUE and SQuAD. For example, ELECTRA-Large achieved an impressive score of 88.7 on the SQuAD 2.0 test set, surpassing models like ALBERT and XLNet.
| Model | SQuAD 2.0 Test Set |
|---|---|
| ELECTRA-Large | 88.7 |
| ALBERT-xxlarge | 88.1 |
| XLNet-Large | 87.9 |
| RoBERTa-Large | 86.8 |
| BERT-Large | 80.0 |
Conclusion
ELECTRA represents a significant advancement in the field of NLP pre-training. Its innovative approach not only enhances efficiency but also maintains high performance across various tasks. The model is available as open-source and supports tasks such as text classification, question answering, and sequence tagging.
Call to Action
Explore the capabilities of ELECTRA and see how it can enhance your NLP projects. For more information, visit the and start leveraging this powerful model today!