
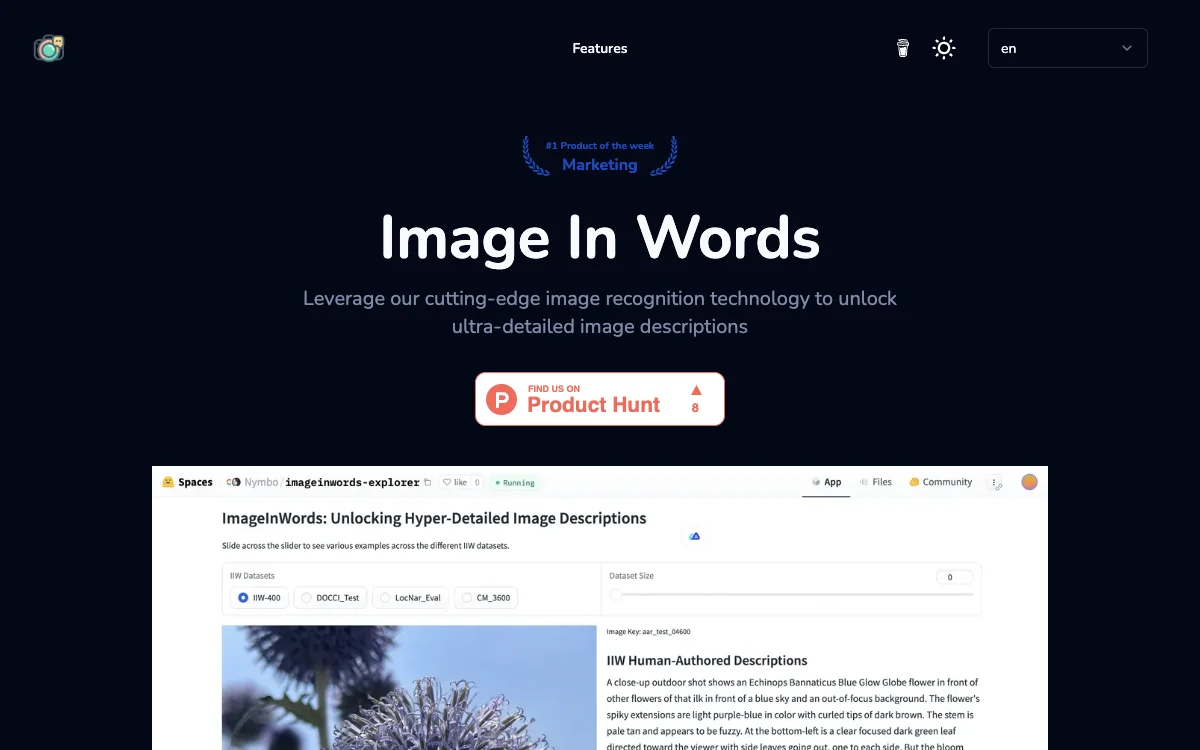
Image In Words representa un avance significativo en la tecnología de reconocimiento de imágenes, ofreciendo una solución innovadora para la generación de descripciones textuales detalladas. Esta herramienta utiliza un modelo generativo que ha sido entrenado con aproximadamente 100,000 horas de datos en inglés, lo que le permite producir descripciones de alta calidad y naturalidad.
Una de las características más destacadas de Image In Words es su capacidad para generar descripciones ultra detalladas. Esto se logra mediante un marco de anotación que involucra a humanos, asegurando que cada descripción sea precisa y rica en detalles. Este enfoque supera las limitaciones de los conjuntos de datos existentes, que a menudo producen descripciones cortas y poco relevantes.
Además, Image In Words ha demostrado una mejora significativa en el rendimiento del modelo. El modelo de lenguaje visual ajustado con datos de IIW muestra un aumento del 31% en la precisión y coherencia de las descripciones en comparación con trabajos anteriores. Esto se debe en parte a la reducción de contenido ficticio en las descripciones, logrado a través de técnicas de verificación rigurosas que aseguran que las descripciones reflejen fielmente los detalles de la imagen.
La legibilidad y la exhaustividad son otros aspectos clave de Image In Words. Las descripciones generadas no solo son detalladas y fáciles de leer, sino que también son comprensibles para una amplia audiencia. Esto se debe a que capturan todos los aspectos relevantes del contenido visual, lo que las hace ideales para una variedad de aplicaciones.
Entre las aplicaciones prácticas de Image In Words se incluyen la mejora de la accesibilidad para usuarios con discapacidad visual, la mejora de las funcionalidades de búsqueda de imágenes y la revisión de contenido más precisa. Estas aplicaciones demuestran el vasto potencial de Image In Words en diferentes campos.
Para aquellos interesados en explorar más a fondo las capacidades de Image In Words, se han lanzado versiones enriquecidas del conjunto de datos IIW-Benchmark Eval, junto con descripciones escritas por humanos y comparaciones con trabajos anteriores. Estos recursos están disponibles bajo la licencia CC-BY-4.0 y pueden ser descargados desde GitHub y Hugging Face en formato 'jsonl'.