
Pré-entraînement de modèles NLP plus efficaces avec ELECTRA
Introduction
Dans le domaine du traitement du langage naturel (NLP), les avancées récentes en matière de pré-entraînement des modèles ont permis d'atteindre des performances remarquables. Parmi ces modèles, ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) se distingue par son efficacité et ses résultats impressionnants. Cet article explore les caractéristiques uniques d'ELECTRA, ses avantages par rapport aux modèles précédents et son impact sur le domaine du NLP.
Qu'est-ce qu'ELECTRA ?
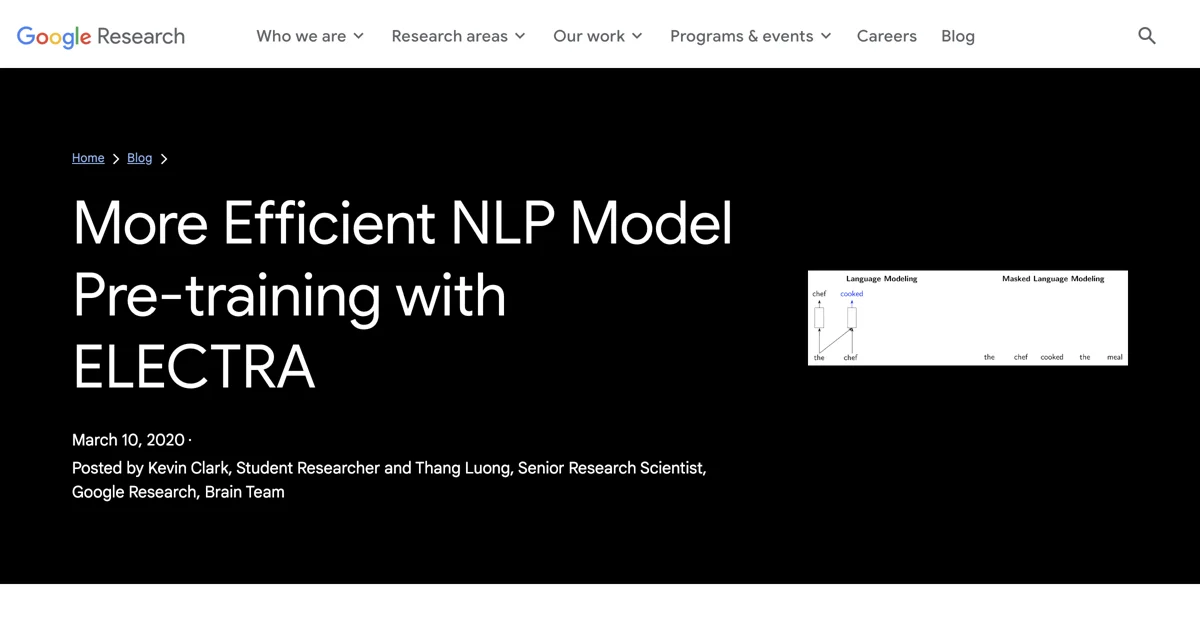
ELECTRA est une méthode de pré-entraînement qui surpasse les techniques existantes tout en utilisant le même budget de calcul. Contrairement aux modèles traditionnels comme BERT et GPT, qui se concentrent sur la prédiction de mots masqués ou sur le traitement unidirectionnel du texte, ELECTRA adopte une approche différente en se basant sur la détection de tokens remplacés (RTD).
Comment fonctionne ELECTRA ?
ELECTRA utilise un modèle bidirectionnel qui apprend à partir de toutes les positions d'entrée, tout en s'inspirant des réseaux antagonistes génératifs (GAN). Au lieu de remplacer des tokens par des masques, ELECTRA remplace certains tokens par des faux plausibles. Par exemple, le mot "cuit" pourrait être remplacé par "mangé". Le modèle doit alors déterminer quels tokens ont été remplacés, ce qui lui permet d'apprendre de manière plus efficace.
Avantages d'ELECTRA
- Efficacité accrue : ELECTRA nécessite moins d'exemples pour atteindre des performances comparables à celles des modèles plus grands, car il reçoit un signal d'entraînement plus fort par exemple.
- Performances supérieures : Sur des benchmarks tels que GLUE et SQuAD, ELECTRA a montré des résultats impressionnants, surpassant des modèles comme RoBERTa et XLNet tout en utilisant moins de ressources de calcul.
- Accessibilité : ELECTRA peut être entraîné sur une seule GPU en quelques jours, rendant la technologie accessible même pour des projets de petite envergure.
Comparaison avec d'autres modèles
| Modèle | Score SQuAD 2.0 | Budget de calcul utilisé |
|---|---|---|
| ELECTRA-Large | 88.7 | 10% de T5 |
| ALBERT-xxlarge | 88.1 | 30% de RoBERTa |
| XLNet-Large | 87.9 | 25% de RoBERTa |
| RoBERTa-Large | 86.8 | 100% |
| BERT-Large | 80.0 | 100% |
Conclusion
ELECTRA représente une avancée significative dans le domaine du pré-entraînement des modèles NLP. Grâce à son approche innovante et à son efficacité, il ouvre la voie à de nouvelles possibilités pour les chercheurs et les développeurs. Nous encourageons les lecteurs à explorer ELECTRA et à l'intégrer dans leurs projets de traitement du langage naturel.
Appel à l'action
Pour en savoir plus sur ELECTRA et accéder aux modèles pré-entraînés, visitez le site officiel de Google Research. Ne manquez pas l'occasion de découvrir comment ELECTRA peut transformer vos projets NLP !