
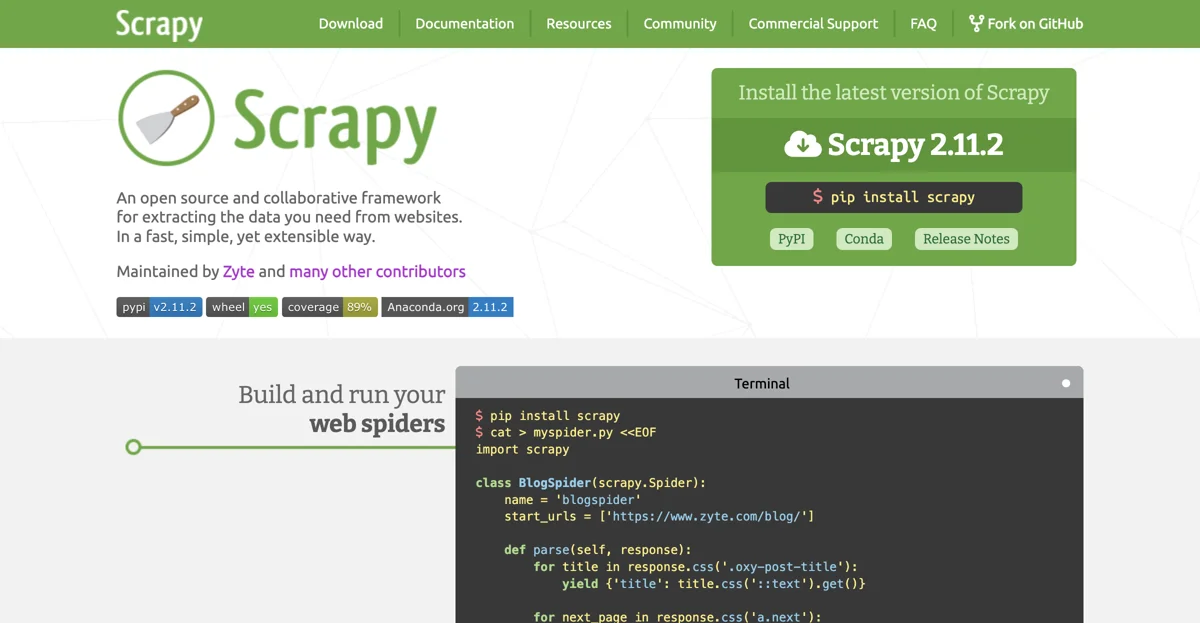
Scrapy est un framework très utile pour l'extraction de données à partir des sites web. Il offre une manière rapide, simple et extensible de réaliser cette tâche. Développé et maintenu par Zyte et de nombreux autres contributeurs, Scrapy est un outil puissant dans le domaine du web scraping et du crawling.
Pour commencer à utiliser Scrapy, il suffit d'installer la dernière version. Par exemple, avec pip, on peut exécuter la commande pip install scrapy pour obtenir Scrapy 2.11.2. Une fois installé, on peut commencer à construire nos spiders web. Par exemple, en créant un fichier myspider.py avec le code suivant :
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://www.zyte.com/blog/']
def parse(self, response):
for title in response.css('.oxy-post-title'):
yield {'title': title.css('::text').get()}
for next_page in response.css('a.next'):
yield response.follow(next_page, self.parse)
On peut ensuite exécuter ce spider avec la commande scrapy runspider myspider.py. Cela permet d'extraire les titres des articles du blog spécifié.
Scrapy offre également la possibilité de déployer les spiders sur le cloud Zyte Scrapy Cloud. Pour cela, on doit d'abord installer shub avec pip install shub, puis se connecter avec shub login en insérant la clé API de Zyte Scrapy Cloud. On peut ensuite déployer le spider avec shub deploy et le programmer pour l'exécution avec shub schedule. On peut également récupérer les données extraites avec shub items.
Scrapy est un outil très puissant et flexible. Il est rapide et permet d'écrire facilement les règles pour extraire les données, et il s'occupe du reste. Il est également extensible par design, ce qui signifie qu'on peut ajouter de nouvelles fonctionnalités facilement sans toucher au cœur du framework. De plus, étant écrit en Python, il est portable et peut s'exécuter sur Linux, Windows, Mac et BSD.
Le projet Scrapy bénéficie également d'une communauté active, avec 43 100 étoiles, 9 600 forks et 1 800 abonnés sur GitHub, 5 500 followers sur Twitter et 18 000 questions sur StackOverflow. Cela montre l'intérêt que suscite cet outil dans le milieu du développement web et du data mining.