
CM3leonは、テキストと画像の生成において、効率的で最先端の生成モデルとして紹介されています。このモデルは、テキストから画像、画像からテキストへの生成を単一の基盤モデルで行うことができ、その多様性と効果性が特徴です。CM3leonは、大規模な検索強化事前学習段階と、多タスク教師あり微調整(SFT)段階を含む、テキストのみの言語モデルから適応されたレシピで訓練されています。このアプローチはシンプルでありながら強力なモデルを生み出し、トークナイザーベースのトランスフォーマーが既存の生成拡散ベースのモデルと同様に効率的に訓練できることを示しています。
CM3leonは、テキストから画像への生成において、以前のトランスフォーマーベースの方法と比較して5倍少ない計算量で訓練されながらも、最先端のパフォーマンスを達成しています。このモデルは、自己回帰モデルの多様性と効果性を維持しつつ、低い訓練コストと推論効率を実現しています。CM3leonは、任意の画像とテキストコンテンツのシーケンスに基づいてテキストと画像のシーケンスを生成できる因果的マスク混合モーダル(CM3)モデルです。これにより、以前のモデルの機能が大幅に拡張されています。
CM3leonは、画像キャプション生成、視覚的質問応答、テキストベースの編集、条件付き画像生成などのタスクにおいて、大規模な多タスク命令チューニングを適用し、パフォーマンスを大幅に向上させています。これにより、テキストのみのモデルで開発されたスケーリングレシピが、トークン化ベースの画像生成モデルに直接一般化できることが示されています。
CM3leonは、最も広く使用されている画像生成ベンチマーク(ゼロショットMS-COCO)において、FID(Fréchet Inception Distance)スコア4.88を達成し、テキストから画像への生成において新しい最先端を確立し、Googleのテキストから画像へのモデルであるPartiを上回りました。この成果は、検索強化の可能性を強調し、自己回帰モデルのパフォーマンスに対するスケーリング戦略の影響を示しています。
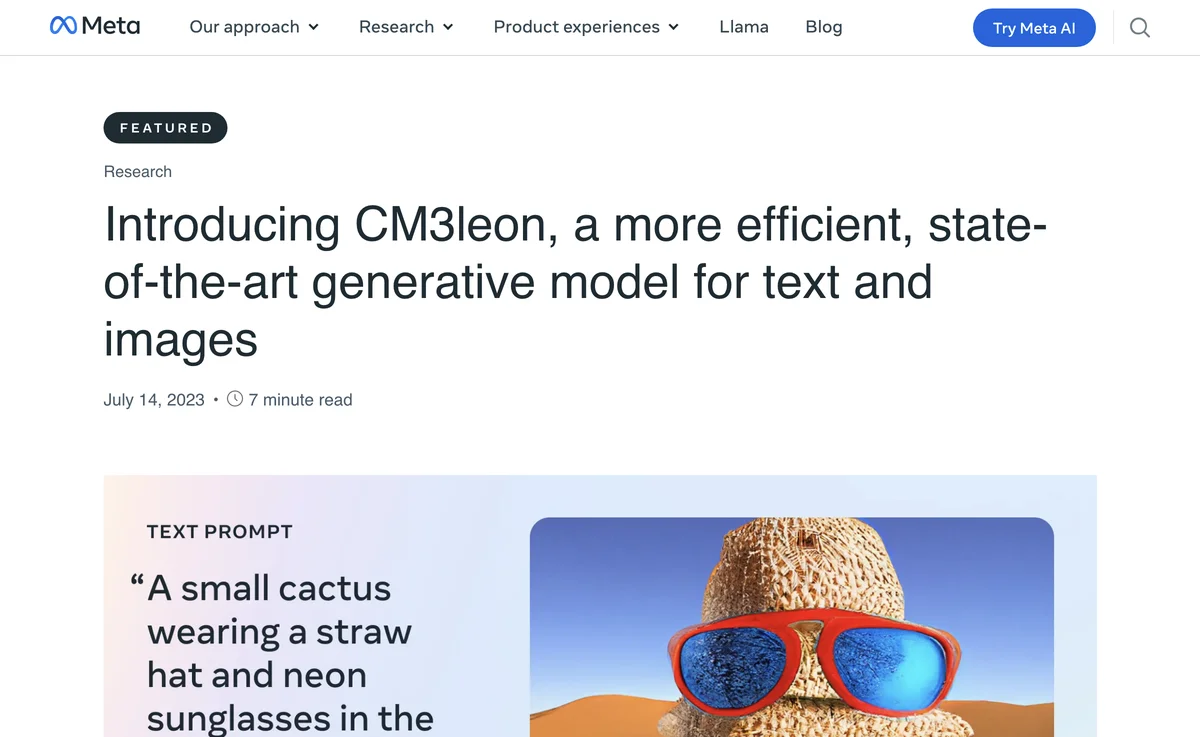
CM3leonは、複雑な構成物の生成においても印象的な能力を示しており、例えば、サングラスと帽子をかぶった鉢植えのサボテンなどの例があります。CM3leonは、視覚的質問応答や長文キャプション作成など、さまざまな視覚言語タスクにおいて優れたパフォーマンスを発揮します。30億のテキストトークンで構成されたデータセットでの訓練にもかかわらず、CM3leonのゼロショットパフォーマンスは、より広範なデータセットで訓練された大規模モデルと比較しても有利です。
CM3leonの能力により、画像生成ツールは、入力プロンプトによりよく従うより一貫性のあるイメージを生成できます。例えば、多くの画像生成モデルは、グローバルな形状とローカルな詳細を回復する能力に苦労していますが、CM3leonはこの領域で強力なパフォーマンスを発揮します。
CM3leonは、単一のモデルでさまざまなタスクを実行できます。これには、テキストガイド付き画像生成と編集、テキストから画像への生成、テキストガイド付き画像編集、テキストタスク、構造ガイド付き画像編集、オブジェクトから画像への生成、セグメンテーションから画像への生成、超解像度結果が含まれます。
CM3leonのアーキテクチャは、確立されたテキストベースのモデルに似たデコーダーのみのトランスフォーマーを使用しています。しかし、CM3leonを際立たせているのは、テキストと画像の両方を入力および生成する能力です。これにより、CM3leonは上記のさまざまなタスクを成功裏に処理できます。
CM3leonの訓練は、検索強化されており、最近の研究に従って、結果として得られるモデルの効率性と制御性を大幅に向上させています。最後に、上記のように、さまざまな画像とテキスト生成タスクに対して命令チューニングを実行しました。
AI業界が進化し続ける中で、CM3leonのような生成モデルはますます洗練されています。これらのモデルは、何百万もの例画像を訓練することで視覚とテキストの関係を学びますが、訓練データに存在するバイアスも反映する可能性があります。業界がこれらの課題を理解し、対処する初期段階にある中で、透明性が進歩を加速する鍵であると信じています。そのため、論文で説明されているように、CM3leonはライセンスされたデータセットを使用して訓練されています。これにより、以前のすべてのモデルが使用したものとは非常に異なるデータ分布で強力なパフォーマンスが可能であることが示されています。私たちの仕事を透明にすることで、生成AIの分野での協力と革新を促進することを願っています。私たちは、協力して、より正確で、すべての人にとってより公平で公正なモデルを作成できると信じています。
高品質な生成モデルを作成することを目指して、CM3leonのさまざまなタスクにおける強力なパフォーマンスは、より高精度な画像生成と理解に向けた一歩であると考えています。CM3leonのようなモデルは、最終的にはメタバースでの創造性とより良いアプリケーションを促進するのに役立つ可能性があります。私たちは、マルチモーダル言語モデルの境界を探求し、将来さらに多くのモデルをリリースすることを楽しみにしています。