
より効率的なNLPモデルの事前学習:ELECTRA
概要
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)は、自然言語処理(NLP)の分野における最新の事前学習手法です。この手法は、従来のモデルに比べてはるかに効率的に学習を行い、同じ計算リソースで優れたパフォーマンスを発揮します。
事前学習の背景
最近の言語事前学習の進展により、BERTやRoBERTa、XLNetなどの最先端モデルが登場しました。これらのモデルは、大量のラベルなしテキストを利用して言語理解の一般モデルを構築し、その後、特定のNLPタスクに微調整されます。従来の事前学習手法は、主に2つのカテゴリに分類されます:
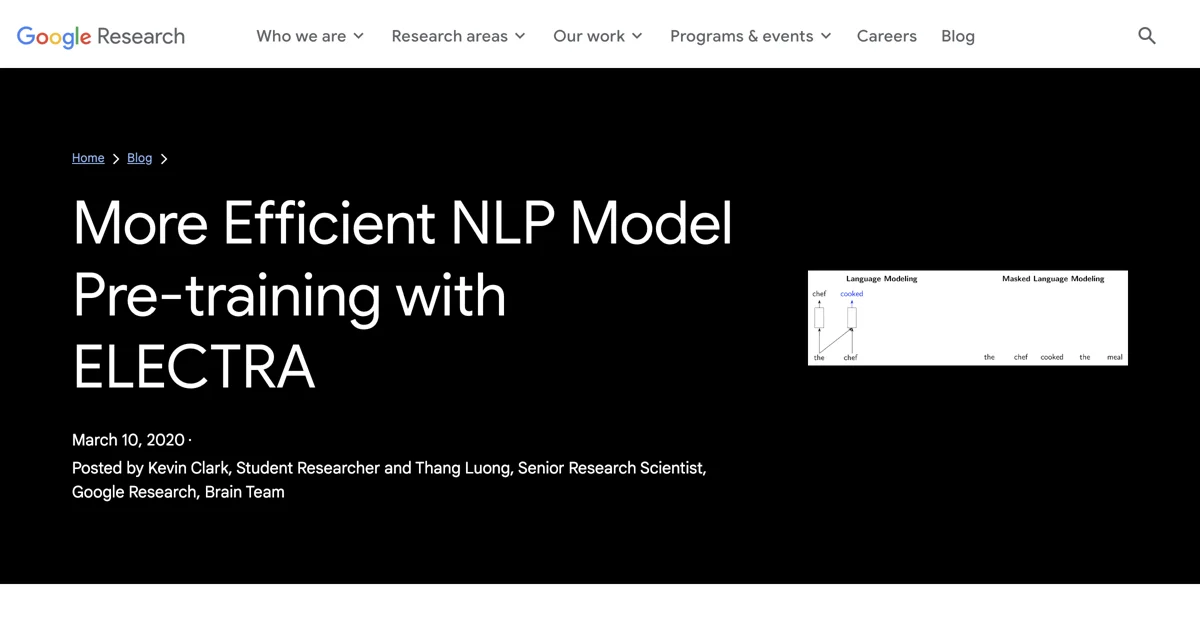
- 言語モデル(LM):GPTのように、入力テキストを左から右に処理し、前の文脈に基づいて次の単語を予測します。
- マスク言語モデル(MLM):BERTやRoBERTaのように、入力からマスクされた単語の識別を予測します。
MLMは双方向であるため、予測されるトークンの左右の文脈を考慮しますが、マスクされたトークンのごく一部しか予測しないため、学習効率が低下します。
ELECTRAのアプローチ
ELECTRAは、BERTの利点を活かしつつ、より効率的に学習を行う新しい事前学習手法です。ELECTRAは、同じ計算リソースを使用しても、RoBERTaやXLNetと同等のパフォーマンスを発揮します。例えば、ELECTRAはGLUE自然言語理解ベンチマークで、RoBERTaやXLNetと同等の結果を出しながら、計算リソースは1/4未満で済みます。
事前学習タスク:置換トークン検出(RTD)
ELECTRAは、置換トークン検出(RTD)という新しい事前学習タスクを使用します。このタスクでは、双方向モデルを訓練し、すべての入力位置から学習します。GAN(生成対抗ネットワーク)に触発されたELECTRAは、モデルに「本物」と「偽物」の入力データを区別させるように訓練します。
ELECTRAの結果
ELECTRAは、他の最先端NLPモデルと比較して、同じ計算リソースで大幅に改善されていることがわかりました。ELECTRAは、RoBERTaやXLNetと同等のパフォーマンスを発揮しながら、計算リソースは25%未満で済みます。さらに、ELECTRA-smallモデルは、単一のGPUで4日間の訓練で良好な精度を達成します。
リリースと今後の展望
ELECTRAのコードは、事前学習と下流タスクへの微調整のためにリリースされます。現在、テキスト分類、質問応答、シーケンスタギングなどのタスクがサポートされています。将来的には、多言語で事前学習されたモデルのリリースを予定しています。
まとめ
ELECTRAは、NLPの事前学習における新しいアプローチを提供し、効率的に学習することで、より高いパフォーマンスを実現します。ぜひ、ELECTRAを試してみて、その効果を実感してください!