
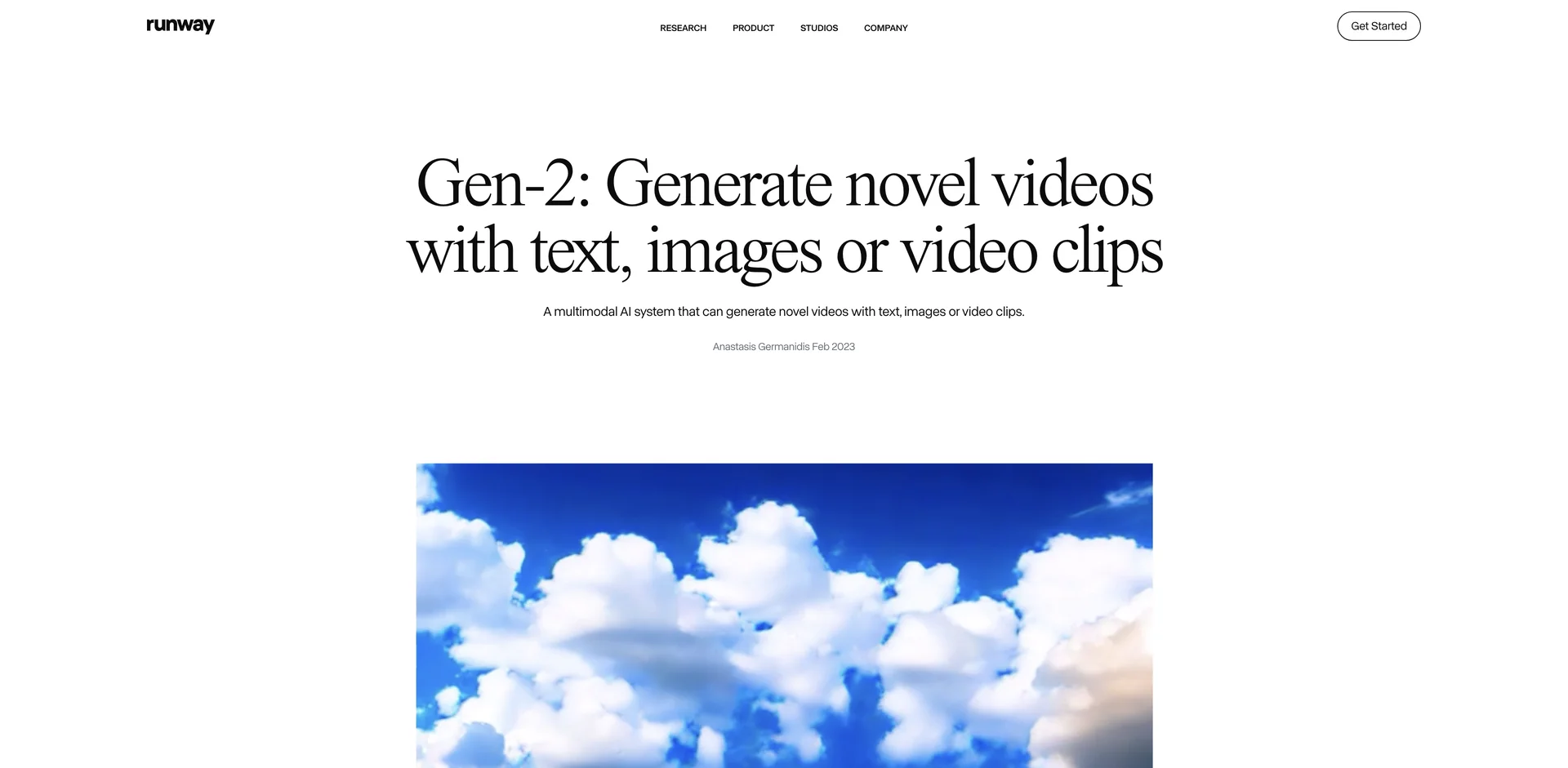
Runway Research Gen-2 は非常に革新的なマルチモーダルAIシステムです。このシステムは、テキスト、画像またはビデオクリップを使って新しいビデオを生成することができます。
たとえば、画像またはテキストのプロンプトの構成とスタイルをソースビデオの構造に適用することで(ビデオからビデオ)、または単に言葉だけを使って(テキストからビデオ)、現実的かつ一貫して新しいビデオを合成できます。これは、何も撮影せずにまるで新しいものを撮影しているようなものです。
Gen-2にはいくつかのモードがあります。モード01では、テキストプロンプトだけを使って想像できるどんなスタイルのビデオも合成できます。言うことができれば、見ることもできます。たとえば「午後遅くの太陽がニューヨーク市のロフトの窓から差し込む」というプロンプトがあります。
モード02では、ドライビングイメージとテキストプロンプトを使ってビデオを生成します。例えば「低角度で男が通りを歩いているショットで、周りのネオンサインに照らされている」というプロンプトがあります。
モード03では、単にドライビングイメージを使ってビデオを生成します(バリエーションモード)。
モード04では、どんな画像またはプロンプトのスタイルもビデオのすべてのフレームに転送できます。
モード05では、モックアップを完全にスタイライズされたアニメーションレンダーに変換できます。
モード06では、モックアップを完全にスタイライズされたアニメーションレンダーに変換できます。
モード07では、入力画像またはプロンプトを適用して、テクスチャのないレンダーをリアルな出力に変換できます。
モード08では、Gen-1のモデルをカスタマイズして、さらに高い忠実度の結果を得ることができます。
ユーザー調査に基づいて、GEN-1の結果は、画像から画像、ビデオからビデオの翻訳に関して既存の方法よりも好まれています。
Runway Researchは、新しい創造性の形を可能にするマルチモーダルAIシステムの構築に専念しており、Gen-1はこのミッションにおけるもう一つの重要な前進です。