
더 효율적인 NLP 모델: ELECTRA의 사전 학습
소개
ELECTRA는 자연어 처리(NLP) 분야에서 혁신적인 사전 학습 방법으로, 기존 모델보다 훨씬 효율적으로 학습할 수 있는 능력을 제공합니다. 이 모델은 BERT와 같은 기존의 마스크 언어 모델(MLM)의 장점을 활용하면서도, 더 많은 정보를 학습할 수 있는 새로운 접근 방식을 채택하고 있습니다.
주요 특징
- 효율적인 학습: ELECTRA는 기존의 사전 학습 방법보다 적은 계산 자원으로도 뛰어난 성능을 발휘합니다. 예를 들어, ELECTRA는 RoBERTa 및 XLNet과 유사한 성능을 내면서도 1/4의 계산 자원만을 사용합니다.
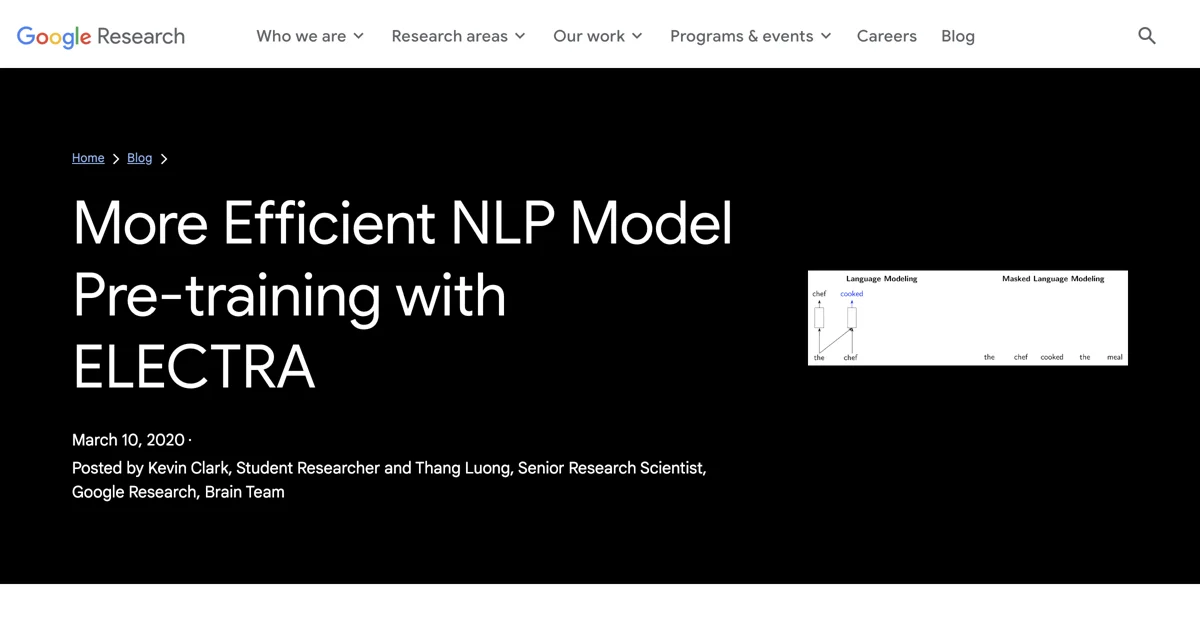
- 대체 토큰 탐지: ELECTRA는 대체 토큰 탐지(RTD)라는 새로운 사전 학습 작업을 통해 모든 입력 위치에서 학습을 진행합니다. 이는 모델이 입력 데이터의 분포를 정확하게 이해하도록 돕습니다.
- 빠른 훈련: ELECTRA는 단일 GPU에서 며칠 내에 훈련할 수 있으며, GPT보다 더 높은 정확도를 달성할 수 있습니다.
사용 사례
ELECTRA는 텍스트 분류, 질문 응답, 시퀀스 태깅 등 다양한 NLP 작업에 활용될 수 있습니다. 이 모델은 특히 대규모 데이터셋에서 뛰어난 성능을 발휘하며, 여러 언어에 대한 지원도 계획하고 있습니다.
가격
ELECTRA는 오픈 소스로 제공되며, 사용자는 무료로 모델을 다운로드하고 사용할 수 있습니다.
비교
ELECTRA는 기존의 NLP 모델들과 비교했을 때, 동일한 계산 예산 내에서 훨씬 더 효율적으로 학습합니다. 예를 들어, SQuAD 2.0 질문 응답 데이터셋에서 ELECTRA-Large는 88.7의 점수를 기록하며, RoBERTa-Large(86.8) 및 XLNet-Large(87.9)를 초월합니다.
고급 팁
- ELECTRA 모델을 사용할 때는 사전 훈련된 가중치를 활용하여 빠르게 다운스트림 작업에 적응할 수 있습니다.
- 다양한 언어에 대한 모델을 훈련시키는 것이 향후 목표입니다.
결론
ELECTRA는 자연어 처리 분야에서의 혁신적인 접근 방식을 제공하며, 효율성과 정확성을 동시에 만족시키는 모델입니다. 이 모델은 NLP 작업을 수행하는 데 있어 새로운 기준을 제시하고 있습니다.