
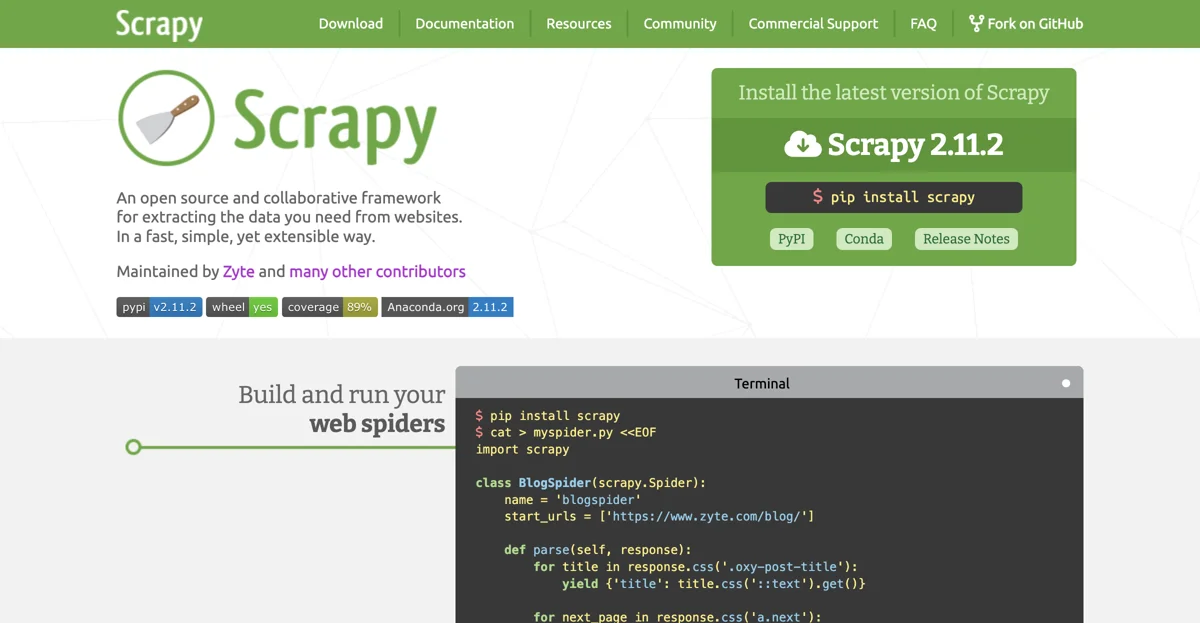
Scrapy는 웹에서 데이터를 추출하기 위한 강력한 오픈 소스 및 협업 프레임워크입니다. 이 프레임워크는 빠르고 간단하면서도 확장 가능한 방식으로 작동하여 사용자가 원하는 데이터를 쉽게 얻을 수 있습니다.
먼저 Scrapy를 설치해야 합니다. Scrapy 2.11.2 버전을 설치하기 위해서는 pip install scrapy 명령을 사용할 수 있습니다. 또한 PyPI나 Conda와 같은 다양한 방법으로도 설치할 수 있습니다.
Scrapy를 사용하여 웹 스파이더를 만들고 실행하는 과정을 살펴보겠습니다. 예를 들어, 다음과 같은 코드를 작성할 수 있습니다.
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://www.zyte.com/blog/']
def parse(self, response):
for title in response.css('.oxy-post-title'):
yield {'title': title.css('::text').get()}
for next_page in response.css('a.next'):
yield response.follow(next_page, self.parse)
위 코드는 blogspider라는 이름의 스파이더를 생성하고, https://www.zyte.com/blog/ 주소에서 시작하여 해당 페이지의 제목을 추출하는 기능을 가지고 있습니다.
Scrapy를 실행하기 위해서는 scrapy runspider myspider.py와 같은 명령을 사용합니다. 또한 Zyte Scrapy Cloud를 사용하여 스파이더를 배포하고 실행할 수도 있습니다. 먼저 shub login 명령을 사용하여 API 키를 입력한 후, shub deploy 명령으로 스파이더를 배포하고, shub schedule 명령으로 실행을 예약할 수 있습니다.
Scrapy는 여러 가지 장점을 가지고 있습니다. 먼저 빠르고 강력한 데이터 추출 기능을 가지고 있습니다. 사용자는 데이터 추출 규칙을 작성하면 Scrapy가 나머지를 처리해주기 때문에 편리합니다. 또한 쉽게 확장 가능한 구조를 가지고 있어서 새로운 기능을 추가하기 쉽습니다. 이는 코어 부분을 건드리지 않고도 플러그인 형태로 새로운 기능을 연결할 수 있음을 의미합니다.
또한 Scrapy는 휴대성이 뛰어납니다. Python으로 작성되어 Linux, Windows, Mac, BSD 등 다양한 운영체제에서 실행할 수 있습니다. 그리고 건강한 커뮤니티를 가지고 있습니다. GitHub에서는 43,100개의 스타, 9,600개의 포크, 1,800개의 감시자가 있으며, Twitter에서는 5,500명의 팔로워가 있고, StackOverflow에서는 18,000개의 질문이 있습니다.
Scrapy는 Zyte와 많은 기타 기여자들에 의해 유지되고 있습니다. 이를 통해 계속해서 발전하고 개선될 수 있습니다.