
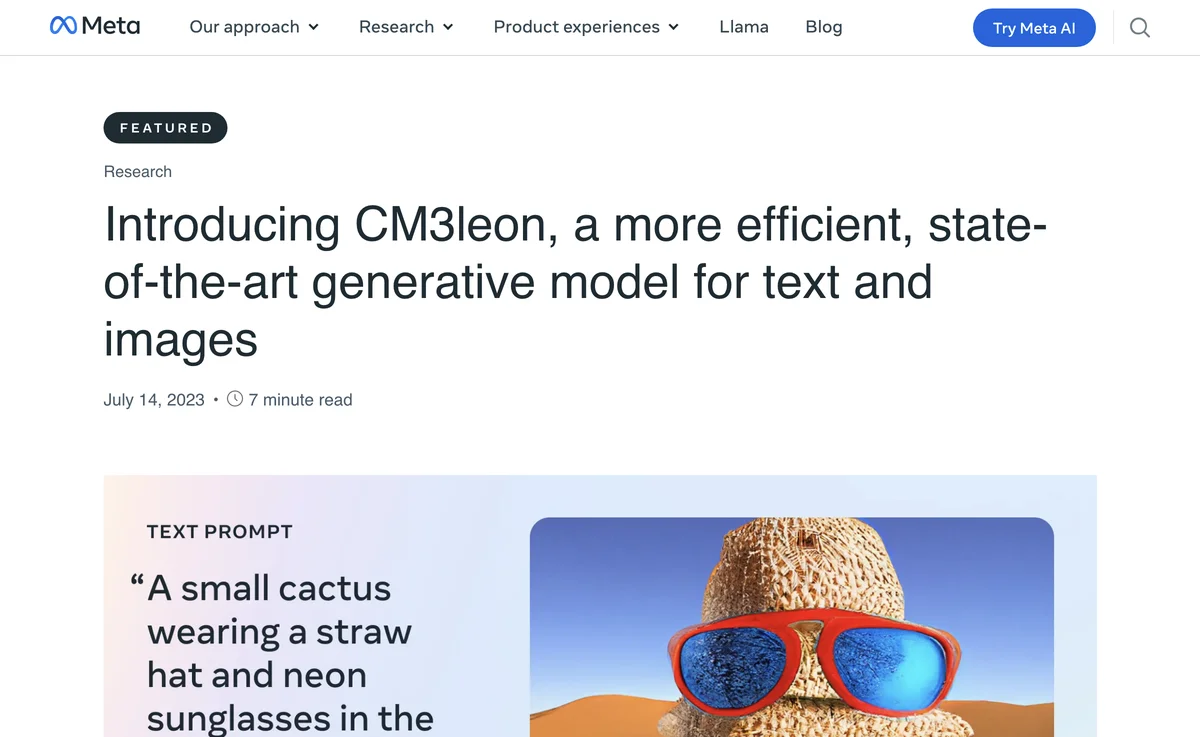
CM3leon 是一款具有开创性的生成模型,在自然语言处理和图像生成领域展现出卓越的性能。它是首个采用从纯文本语言模型改编的配方进行训练的多模态模型,包括大规模的检索增强预训练阶段和多任务监督微调阶段。这一配方不仅简单,还能生成强大的模型,同时表明基于标记器的转换器可以像现有的基于生成扩散的模型一样高效地进行训练。
CM3leon 在文本到图像生成方面达到了最先进的性能,尽管其训练计算量比以前的基于转换器的方法少了五倍。它具有自回归模型的多功能性和有效性,同时保持了较低的训练成本和推理效率。它是一个因果掩码混合模态(CM3)模型,能够根据任意的其他图像和文本内容的序列生成文本和图像的序列,大大扩展了以前只能进行文本到图像或图像到文本生成的模型的功能。
CM3leon 在各种视觉语言任务中表现出色,包括视觉问答和长篇描述。即使在仅使用包含三十亿文本标记的数据集进行训练的情况下,CM3Leon 的零样本性能也能与在更广泛的数据集上训练的更大模型相媲美。它在文本引导的图像生成和编辑、文本到图像生成、文本任务以及结构引导的图像编辑等多种任务中都表现出强大的能力。
CM3leon 的架构使用了类似于成熟的基于文本的模型的仅解码器转换器,但它能够输入和生成文本和图像。其训练采用了检索增强的方法,提高了效率和可控性,并在各种图像和文本生成任务上进行了指令微调。随着 AI 行业的不断发展,像 CM3leon 这样的生成模型将变得越来越复杂,为图像生成和理解领域带来更高的保真度。