
CM3leon representa um avanço significativo no campo da inteligência artificial generativa, oferecendo uma abordagem inovadora para a geração de texto e imagens. Este modelo multimodal, que se pronuncia como "camaleão", é o primeiro do seu tipo a ser treinado com uma receita adaptada de modelos de linguagem baseados apenas em texto, incluindo uma fase de pré-treinamento ampliada por recuperação e uma segunda fase de ajuste fino supervisionado multitarefa (SFT).
A eficiência do CM3leon é notável, alcançando desempenho de última geração na geração de texto para imagem, apesar de ser treinado com cinco vezes menos computação do que os métodos anteriores baseados em transformadores. Sua versatilidade e eficácia são comparáveis aos modelos autoregressivos, mantendo baixos custos de treinamento e eficiência de inferência.
O modelo CM3leon é capaz de gerar sequências de texto e imagens condicionadas a sequências arbitrárias de outros conteúdos de imagem e texto, expandindo significativamente a funcionalidade dos modelos anteriores que eram limitados a apenas texto para imagem ou imagem para texto. A aplicação de ajuste fino de instruções multitarefa em grande escala ao CM3leon para geração de imagem e texto demonstra uma melhoria significativa no desempenho em tarefas como geração de legendas de imagem, resposta a perguntas visuais, edição baseada em texto e geração condicional de imagens.
Comparando o desempenho no benchmark de geração de imagem mais amplamente utilizado (zero-shot MS-COCO), o CM3leon alcança uma pontuação FID (Fréchet Inception Distance) de 4.88, estabelecendo um novo padrão de excelência na geração de texto para imagem e superando o modelo de texto para imagem do Google, Parti. Essa conquista sublinha o potencial da recuperação ampliada e destaca o impacto das estratégias de escalonamento no desempenho dos modelos autoregressivos.
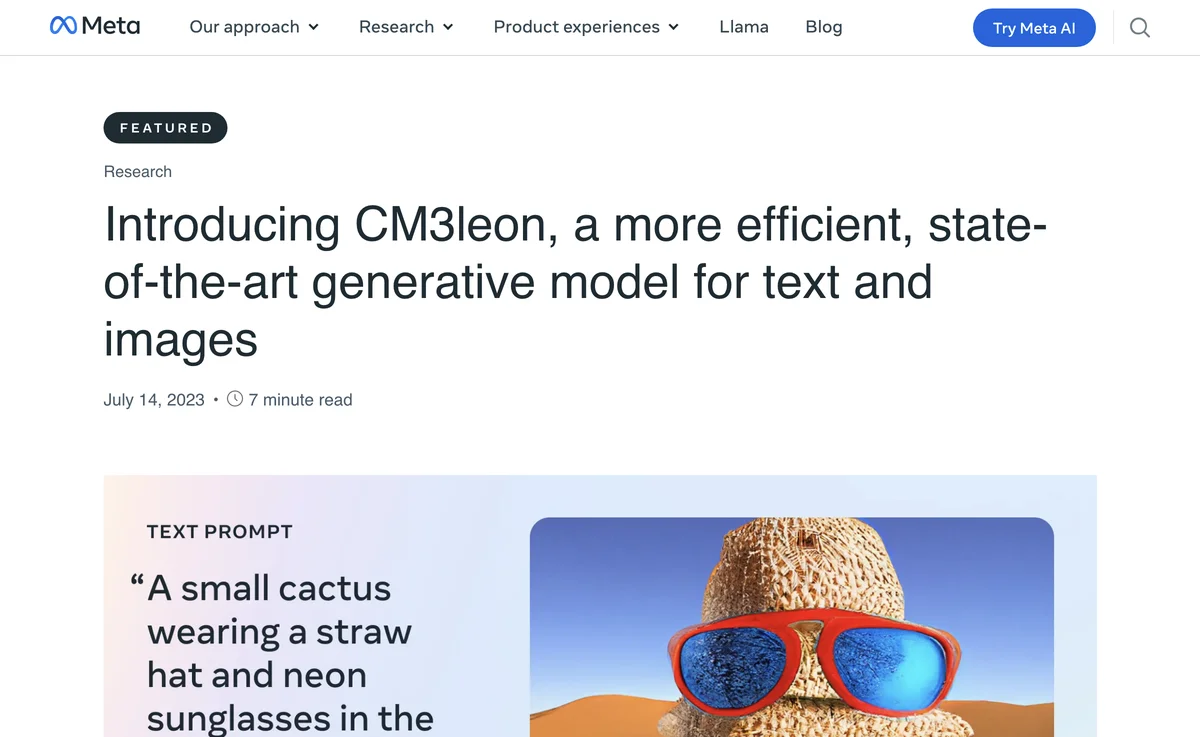
CM3leon também demonstra uma capacidade impressionante de gerar objetos composicionais complexos, como um cacto em vaso com óculos de sol e chapéu, e se sai bem em uma variedade de tarefas de linguagem visual, incluindo resposta a perguntas visuais e legendagem de longa duração. Mesmo com o treinamento em um conjunto de dados composto por apenas três bilhões de tokens de texto, o desempenho zero-shot do CM3leon se compara favoravelmente a modelos maiores treinados em conjuntos de dados mais extensos.
A arquitetura do CM3leon utiliza um transformador somente decodificador, semelhante aos modelos baseados em texto bem estabelecidos, mas o que diferencia o CM3leon é sua capacidade de inserir e gerar tanto texto quanto imagens. Isso capacita o CM3leon a lidar com sucesso com a variedade de tarefas mencionadas acima. O treinamento do CM3leon é ampliado por recuperação, seguindo nosso trabalho recente, melhorando muito a eficiência e a controlabilidade do modelo resultante. Finalmente, como descrito acima, realizamos o ajuste fino de instruções em uma ampla gama de diferentes tarefas de geração de imagem e texto.
À medida que a indústria de IA continua a evoluir, modelos generativos como o CM3leon estão se tornando cada vez mais sofisticados. Esses modelos aprendem a relação entre visuais e texto treinando em milhões de imagens de exemplo, mas também podem refletir quaisquer vieses presentes nos dados de treinamento. Enquanto a indústria ainda está em seus estágios iniciais de compreensão e abordagem desses desafios, acreditamos que a transparência será fundamental para acelerar o progresso. Como tal, e como descrito em nosso artigo, treinamos o CM3leon usando um conjunto de dados licenciado. Isso demonstra que um forte desempenho é possível com uma distribuição de dados muito diferente daquela usada por todos os modelos anteriores. Ao tornar nosso trabalho transparente, esperamos encorajar a colaboração e a inovação no campo da IA generativa. Acreditamos que, trabalhando juntos, podemos criar modelos que não sejam apenas mais precisos, mas também mais justos e equitativos para todos.