
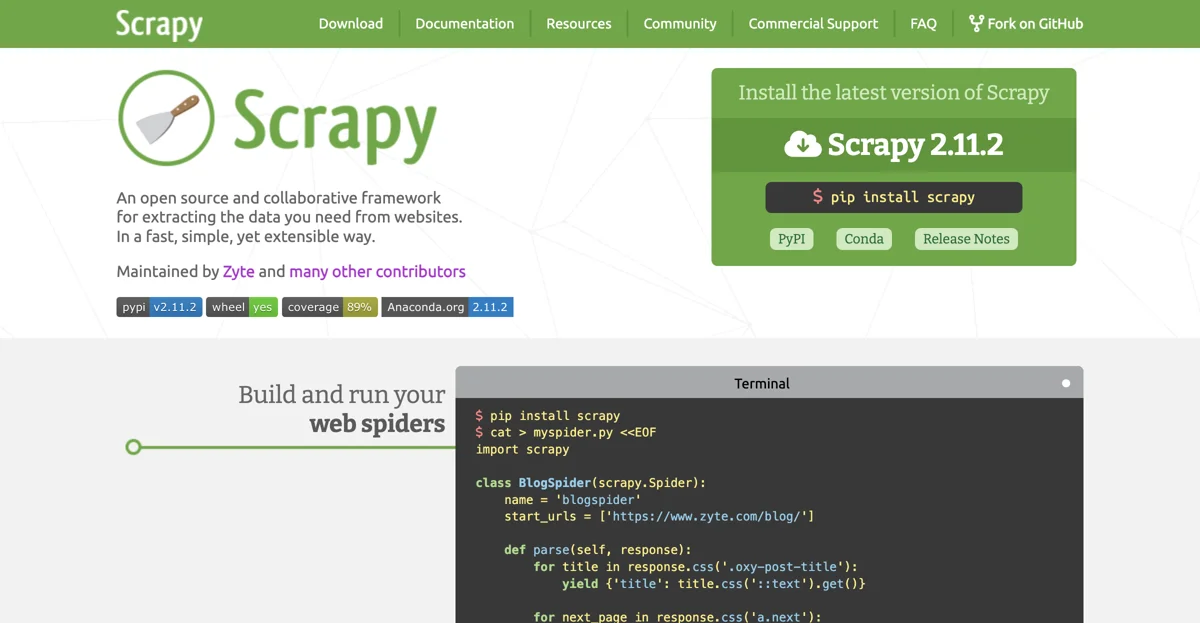
Scrapy é um framework extremamente útil para a extração de dados de websites. Ele oferece uma maneira rápida, simples e, ao mesmo tempo, extensível de obter as informações desejadas.
Para começar a usar Scrapy, é possível instalar a versão mais recente, no caso, a Scrapy 2.11.2, através do comando pip install scrapy no terminal. Depois de instalado, é possível criar spiders web, como o exemplo do BlogSpider mostrado abaixo:
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://www.zyte.com/blog/']
def parse(self, response):
for title in response.css('.oxy-post-title'):
yield {'title': title.css('::text').get()}
for next_page in response.css('a.next'):
yield response.follow(next_page, self.parse)
Esse spider vai acessar o blog da Zyte e extrair os títulos dos posts. Para executar esse spider, basta usar o comando scrapy runspider myspider.py.
Além disso, é possível implantar esses spiders no Zyte Scrapy Cloud. Primeiro, é necessário instalar o shub e fazer login, inserindo a chave API do Zyte Scrapy Cloud. Depois, é possível implantar o spider com o comando shub deploy e agendar sua execução com shub schedule blogspider. E para recuperar os dados raspados, usa-se o comando shub items 26731/1/8.
Scrapy possui várias vantagens. É rápido e poderoso, pois basta escrever as regras para extrair os dados e deixar o Scrapy fazer o resto. É também facilmente extensível, pois foi projetado para permitir a inclusão de novas funcionalidades sem a necessidade de mexer no núcleo. É portátil, pois é escrito em Python e roda em Linux, Windows, Mac e BSD.
A comunidade em torno de Scrapy é bastante saudável. Tem mais de 43.100 estrelas, 9.600 forks e 1.800 observadores no GitHub, além de 5.500 seguidores no Twitter e 18.000 perguntas no StackOverflow.
Em resumo, Scrapy é uma ótima opção para quem precisa extrair dados de websites, seja para uso pessoal ou profissional, graças às suas características de rapidez, facilidade de uso e extensibilidade.