
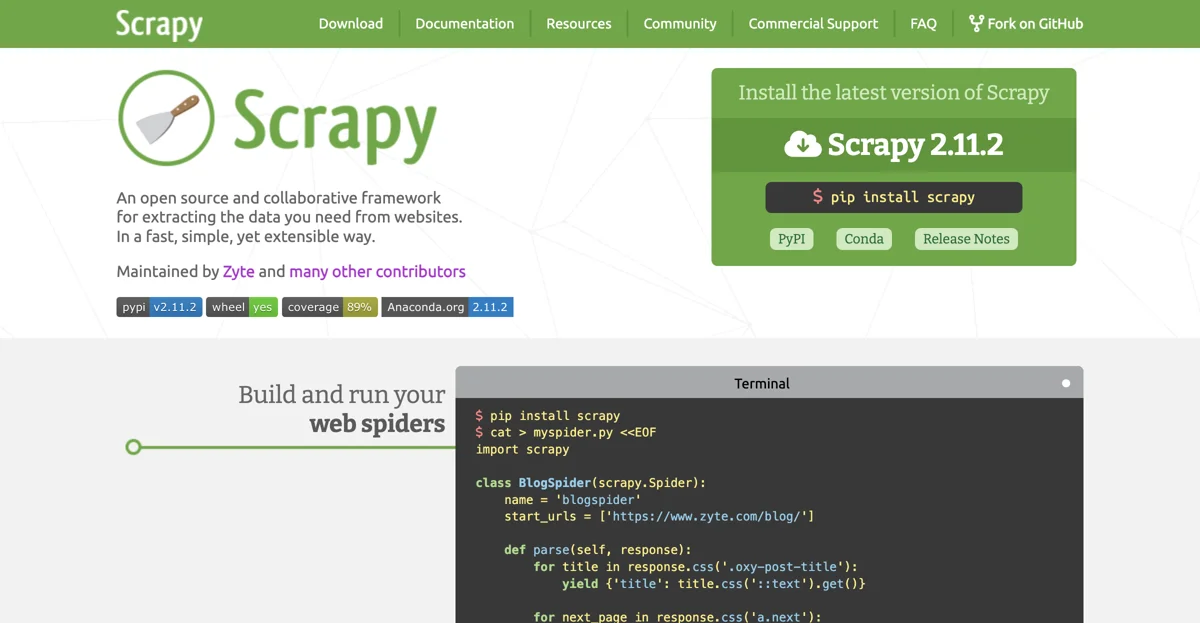
Scrapy представляет собой мощный инструмент для сбора данных с веб-сайтов. Он имеет открытый исходный код и является результатом совместной работы многих разработчиков, включая Zyte и других участников проекта.
Установка Scrapy довольно проста. Например, для установки последней версии Scrapy 2.11.2 можно использовать команду pip install scrapy в терминале. После установки можно приступать к созданию и запуску своих веб-пауков (spiders).
Для создания своего паука, как в примере выше, можно определить класс, наследующий от scrapy.Spider. В этом классе указываются начальные URL-адреса для сбора данных и методы для обработки полученных ответов от сайтов. Например, в методе parse можно обрабатывать HTML-страницы, находить нужные элементы и извлекать информацию, например, заголовки статей с сайта.
Scrapy позволяет не только создавать и запускать пауков на локальном компьютере, но и развертывать их в облаке. Например, с помощью Zyte Scrapy Cloud можно легко развернуть свой паук. Для этого нужно выполнить шаги авторизации, ввести свой API-ключ Zyte Scrapy Cloud, а затем использовать команды для деплоя и запланирования выполнения паука.
Одним из главных преимуществ Scrapy является его скорость и мощь. Вы пишете правила для извлечения данных, а Scrapy занимается остальным. Он также легко расширяемый. По своей структуре он позволяет легко подключать новую функциональность, не затрагивая ядро фреймворка.
Поскольку Scrapy написан на Python, он является переносимым и может работать на различных операционных системах, таких как Linux, Windows, Mac и BSD.
Еще одним важным аспектом является наличие здоровой и активной сообщества вокруг Scrapy. На GitHub есть большое количество звезд, форков и наблюдателей, а на Twitter и StackOverflow также есть много людей, интересующихся и использующих этот инструмент. Многие компании также используют Scrapy для своих нужд по сборе данных с веб-сайтов.
В целом, Scrapy - это отличный выбор для тех, кто нуждается в быстром и эффективном инструменте для сбора данных с веб-сайтов, обладающем широкими возможностями и поддержкой активного сообщества.