
更高效的NLP模型预训练:ELECTRA
在自然语言处理(NLP)领域,语言预训练的最新进展带来了显著的提升,尤其是像BERT、RoBERTa、XLNet、ALBERT和T5等先进模型的出现。这些方法虽然在设计上有所不同,但都共享一个理念:利用大量未标记的文本构建通用的语言理解模型,然后在特定的NLP任务上进行微调,如情感分析和问答。
现有预训练方法的局限性
现有的预训练方法通常分为两类:
- 语言模型(LMs):例如GPT,从左到右处理输入文本,根据之前的上下文预测下一个单词。
- 掩码语言模型(MLMs):例如BERT、RoBERTa和ALBERT,预测输入中被掩盖的少量单词。
虽然MLMs在预测时可以“看到”被预测单词左右的文本,但它们的缺点在于只预测小部分被掩盖的单词(通常为15%),这减少了从每个句子中学习到的信息量。
ELECTRA的创新
在《ELECTRA:将文本编码器预训练为鉴别器而非生成器》中,我们提出了一种不同的语言预训练方法,提供了BERT的优势,但学习效率更高。ELECTRA(高效学习分类令牌替换的编码器)是一种新颖的预训练方法,在相同计算预算下超越了现有技术。
例如,ELECTRA在GLUE自然语言理解基准上与RoBERTa和XLNet的表现相当,但计算需求不到它们的四分之一,并在SQuAD问答基准上取得了最先进的结果。ELECTRA的高效性使其即使在小规模下也能表现良好——它可以在单个GPU上训练几天,准确度超过使用30倍计算的GPT。
加快预训练的速度
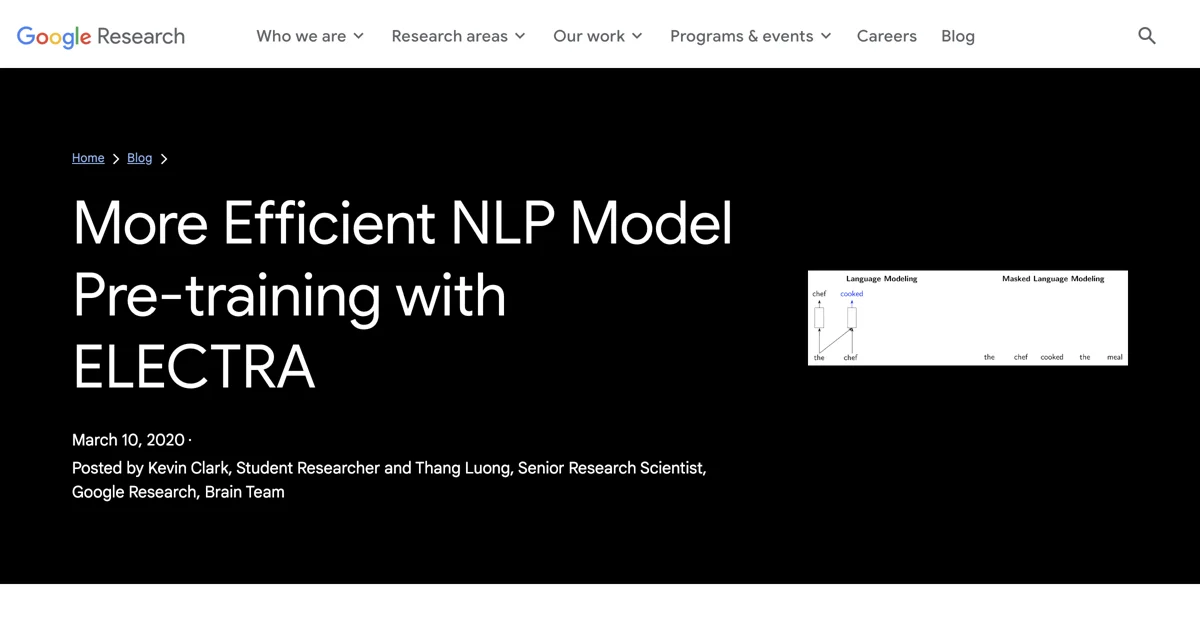
ELECTRA使用了一种新的预训练任务,称为替换令牌检测(RTD),它训练一个双向模型(类似于MLM),同时从所有输入位置学习(类似于LM)。受生成对抗网络(GANs)的启发,ELECTRA训练模型区分“真实”和“虚假”的输入数据。与BERT通过用“[MASK]”替换令牌来破坏输入不同,我们的方法通过用不正确但看似合理的虚假令牌替换某些输入令牌来破坏输入。
例如,单词“cooked”可以被替换为“ate”。虽然这有点道理,但与整个上下文不太匹配。预训练任务要求模型(即鉴别器)确定原始输入中哪些令牌被替换或保持不变。关键在于,这一二元分类任务应用于每个输入令牌,而不仅仅是少量被掩盖的令牌(在BERT模型中为15%),使得RTD比MLM更高效——ELECTRA需要看到更少的示例即可达到相同的性能,因为它从每个示例中获得了更多的训练信号。
ELECTRA的结果
我们将ELECTRA与其他先进的NLP模型进行了比较,发现它在相同的计算预算下显著改善了之前的方法,表现与RoBERTa和XLNet相当,但使用的计算量不到25%。
在GLUE基准上,ELECTRA的表现超越了RoBERTa、XLNet和ALBERT。虽然大规模的T5-11b模型在GLUE上得分更高,但ELECTRA的规模仅为其1/30,训练所需计算量仅为10%。
发布ELECTRA
我们将发布ELECTRA的预训练和微调代码,当前支持的任务包括文本分类、问答和序列标记。代码支持在单个GPU上快速训练小型ELECTRA模型。我们还将发布ELECTRA-Large、ELECTRA-Base和ELECTRA-Small的预训练权重。虽然ELECTRA模型目前仅支持英语,但我们希望未来能发布经过多语言预训练的模型。
结论
ELECTRA的出现为NLP模型的预训练提供了新的思路和方法,凭借其高效性和出色的性能,必将在未来的研究和应用中发挥重要作用。想要了解更多关于ELECTRA的信息,欢迎访问。