
Pre-entrenamiento de Modelos NLP Más Eficientes con ELECTRA
Introducción
En el campo del procesamiento del lenguaje natural (NLP), los avances recientes en el pre-entrenamiento de modelos han llevado a mejoras significativas. Modelos como BERT, RoBERTa y XLNet han establecido nuevos estándares, pero ELECTRA se presenta como una alternativa innovadora que promete una eficiencia superior.
¿Qué es ELECTRA?
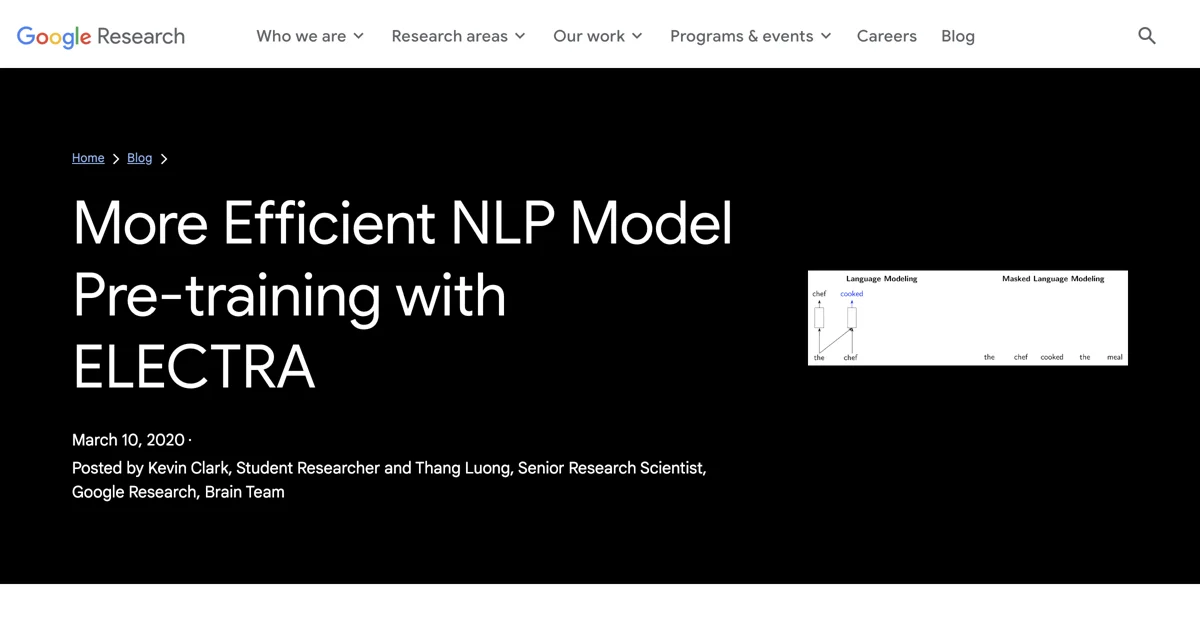
ELECTRA, que significa "Efficiently Learning an Encoder that Classifies Token Replacements Accurately", es un método de pre-entrenamiento que supera a las técnicas existentes utilizando el mismo presupuesto computacional. A diferencia de los modelos de lenguaje tradicionales que solo predicen la siguiente palabra en una secuencia, ELECTRA utiliza un enfoque de detección de tokens reemplazados (RTD) que permite un aprendizaje más eficiente.
Ventajas de ELECTRA
- Eficiencia en el Aprendizaje: ELECTRA puede igualar el rendimiento de RoBERTa y XLNet en el benchmark GLUE utilizando menos de ¼ de su capacidad computacional.
- Entrenamiento Rápido: Se puede entrenar en unos pocos días en una sola GPU, logrando una mejor precisión que modelos que requieren más de 30 veces más computación.
- Modelo Bidireccional: A diferencia de los modelos unidireccionales, ELECTRA considera el contexto de ambos lados de la palabra que se está prediciendo, lo que mejora la comprensión del lenguaje.
Cómo Funciona ELECTRA
ELECTRA introduce una tarea de pre-entrenamiento innovadora llamada detección de tokens reemplazados (RTD). En lugar de enmascarar palabras en la entrada, ELECTRA reemplaza algunas palabras con alternativas plausibles pero incorrectas. Esto obliga al modelo a clasificar cada token de entrada como "real" o "falso", lo que resulta en un aprendizaje más robusto y eficiente.
Comparación con Modelos Existentes
- Modelos de Lenguaje (LM): Procesan el texto de izquierda a derecha, lo que limita su capacidad de contexto.
- Modelos de Lenguaje Enmascarados (MLM): Como BERT, que solo predicen un pequeño subconjunto de palabras enmascaradas, lo que reduce la cantidad de información aprendida.
ELECTRA, al predecir todos los tokens, maximiza la señal de entrenamiento y mejora la representación del lenguaje.
Resultados de ELECTRA
ELECTRA ha demostrado ser superior a otros modelos de NLP en términos de eficiencia. En pruebas comparativas, ELECTRA logró resultados sobresalientes en el conjunto de datos SQuAD 2.0 y en el ranking GLUE, superando a modelos como RoBERTa y XLNet.
| Modelo | Puntaje SQuAD 2.0 |
|---|---|
| ELECTRA-Large | 88.7 |
| ALBERT-xxlarge | 88.1 |
| XLNet-Large | 87.9 |
| RoBERTa-Large | 86.8 |
| BERT-Large | 80.0 |
Conclusión
ELECTRA no solo es un avance en la eficiencia del pre-entrenamiento de modelos NLP, sino que también ofrece un enfoque innovador que podría cambiar la forma en que se desarrollan y utilizan estos modelos en el futuro. Con la liberación de su código y modelos pre-entrenados, ELECTRA está listo para ser utilizado en diversas tareas de NLP.
Llamado a la Acción
Si estás interesado en explorar ELECTRA y sus capacidades, visita el repositorio de ELECTRA en GitHub para obtener más información y comenzar a experimentar con este potente modelo.