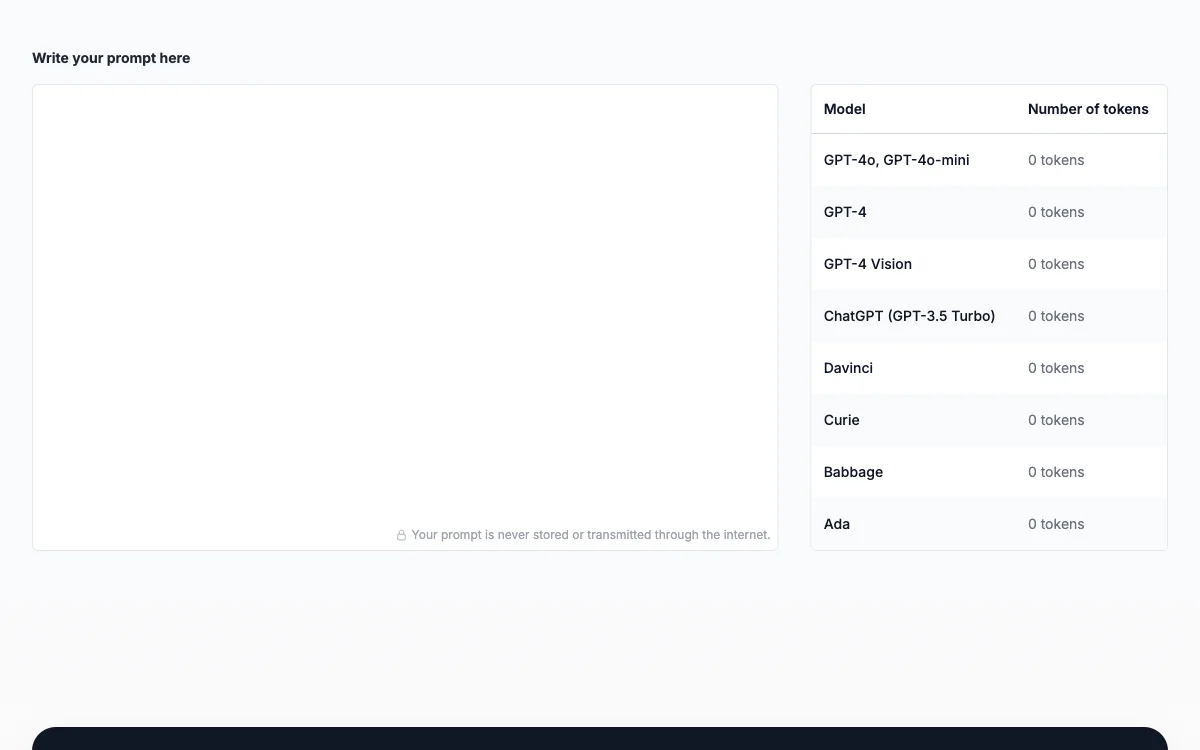
In questo articolo si discute del Prompt Token Counter per i modelli OpenAI. Un token è l'unità più piccola in elaborazione del linguaggio naturale e apprendimento automatico, mentre un prompt è l'input iniziale o l'istruzione al modello. Il Prompt Token Counter è importante perché i modelli come GPT-3.5 hanno limiti di token. Per contare i token del prompt, bisogna conoscere i limiti del modello, preprocessare il prompt, contare i token dopo il preprocessing, considerare i token della risposta. Se il prompt supera il limite, va rifinito e accorciato per rientrare nei limiti.

Prompt Token Counter for OpenAI Models
Scoprite come il Prompt Token Counter aiuta a gestire l'utilizzo dei token nei modelli OpenAI per un'esperienza efficiente e a costo contenuto.
Cos'è Prompt Token Counter for OpenAI ModelsPrompt Token Counter for OpenAI Models AlternativePrompt Token Counter for OpenAI Models Categorie IA
Migliori alternative a Prompt Token Counter for OpenAI Models
PromptLeo
PromptLeo è una piattaforma di ingegneria dei prompt AI che facilita la creazione e gestione dei prompt per i team.
Vidura
Vidura è un manager di prompt AI che dà una spinta alla produttività
OctiAI
OctiAI è il top generatore di prompt AI che spacca! Aumenta la creatività e la produttività.
Redmo
Redmo è un potente strumento per creare prompt con variabili e supporto API
Guida all'Ingegneria dei Prompt
La Guida all'Ingegneria dei Prompt è il tuo go-to per ottimizzare i prompt e far brillare i modelli di linguaggio.
GPT Prompt Tuner
GPT Prompt Tuner è uno strumento AI che aiuta a generare e ottimizzare i prompt per ChatGPT in modo super efficace.
NeoPrompts
NeoPrompts è uno strumento AI-powered che aiuta a ottimizzare i prompts per risultati migliori.
Promptrr.io
Promptrr.io è un mercato di prompt AI per monetizzare e ottimizzare modelli
PromptPort
PromptPort è uno strumento AI che aiuta a generare ottimi prompt per diversi scopi.
BasicPrompt
BasicPrompt è un potente strumento per creare e gestire prompt
Promptcraft
Promptcraft è un costruttore di prompt per chatbot AI open-source e modificabile
L'Istituto di Ingegneria delle Prompt
L'Istituto di Ingegneria delle Prompt offre varie risorse e tutorial sull'IA
Promptologer
Promptologer è un modo per monetizzare i prompt senza codice
Prompt Genie
Prompt Genie trasforma i prompt in risultati straordinari per ChatGPT
PromptsLabs
PromptsLabs è una libreria di prompt per testare nuove LLM
Learn Prompting Pro
Learn Prompting Pro è un corso AI-powered che aiuta a sfruttare GPT-4 per il successo nel marketing.
PromptMage
PromptMage è un framework Python per semplificare lo sviluppo di applicazioni complesse basate su LLM.
endoftext
endoftext è un editor di prompt AI che migliora in pochi minuti
Latitude
Latitude è una piattaforma open-source per l'ingegneria dei prompt che aiuta a creare e migliorare i prompt AI in modo super efficiente.
BetterPrompt
BetterPrompt è uno strumento AI che rende i tuoi prompt di Midjourney super efficaci e creativi.
Promptmetheus
Promptmetheus è un IDE per l'ingegneria dei prompt che aiuta a creare e ottimizzare prompt per applicazioni AI.
Strumenti IA in evidenza
EasyPrompt
EasyPrompt è un'app AI che controlla parole vietate e migliora i prompt per Midjourney.
NeoPrompts
NeoPrompts è uno strumento AI-powered che aiuta a ottimizzare i prompts per risultati migliori.
Prompt Token Counter for OpenAI Models
Prompt Token Counter helps manage token usage for OpenAI models
AI Prompt Randomizer
AI Prompt Randomizer è uno strumento che genera prompt casuali per l'uso con AI generative.
PromptLeo
PromptLeo è una piattaforma di ingegneria dei prompt AI che facilita la creazione e gestione dei prompt per i team.
PromptInterface.ai
PromptInterface.ai è uno strumento di prompt engineering basato su AI che aiuta a creare assistenti personalizzati per aumentare la produttività.
Weavel
Weavel è uno strumento AI che automatizza l'ingegneria dei prompt, ottimizzando rapidamente i prompt per le app LLM.
glideprompt
glideprompt facilita la progettazione dei prompt, aiutando gli utenti a ottenere rapidamente i prompt per i modelli linguistici.