
Scrapy è un framework di scraping e web crawling che offre una soluzione efficace per estrarre i dati necessari dai siti web. È progettato per essere veloce, semplice da usare e allo stesso tempo estensibile.
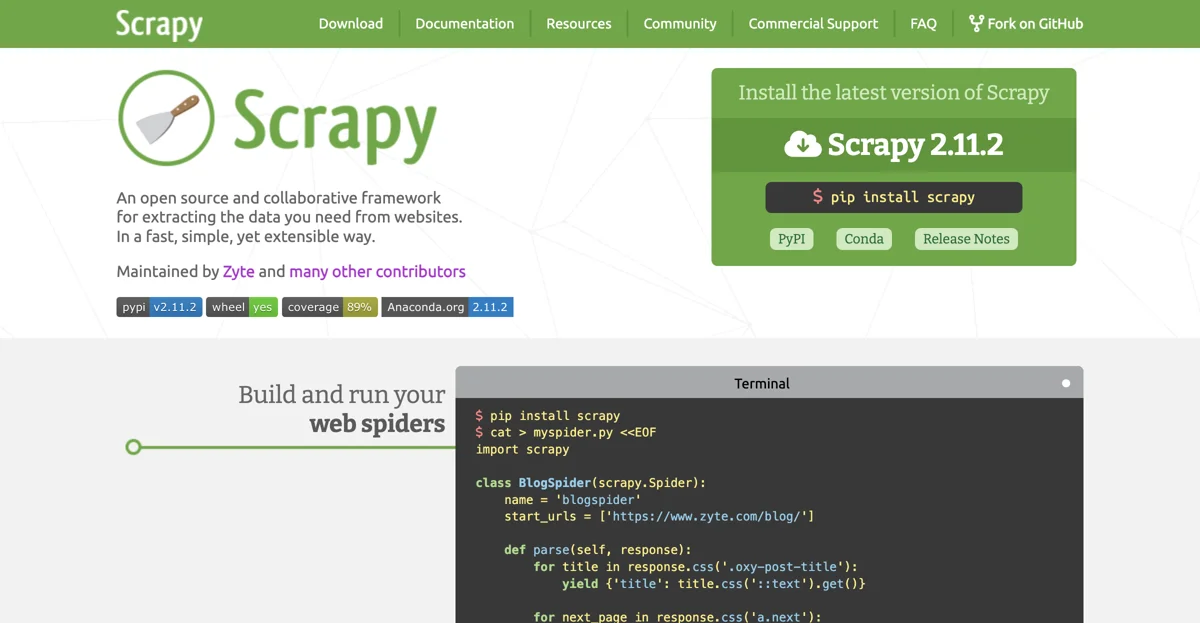
Per iniziare a usare Scrapy, è possibile installare la versione più recente. Ad esempio, con pip install scrapy, è possibile ottenere Scrapy 2.11.2. Inoltre, è disponibile anche su PyPI e Conda.
Una volta installato, è possibile creare i propri web spiders. Come mostrato nel codice di esempio, si può definire una classe che eredita da scrapy.Spider. In questo caso, abbiamo la classe BlogSpider con il nome 'blogspider' e le URL di partenza specificate. Nella funzione parse, si possono estrarre i dati desiderati dai siti web visitati. Ad esempio, si possono recuperare i titoli dei post dal sito web specificato.
Scrapy offre anche la possibilità di eseguire i web spiders direttamente dal terminale. Inoltre, è possibile collegarsi a Zyte Scrapy Cloud per distribuire e pianificare l'esecuzione dei web spiders. Basta inserire la propria chiave API di Zyte Scrapy Cloud e usare i comandi come shub deploy e shub schedule.
Un'altra caratteristica importante di Scrapy è la sua estensibilità. È progettato in modo tale che sia facile aggiungere nuove funzionalità senza dover modificare il codice centrale. Inoltre, essendo scritto in Python, è portabile e può essere eseguito su vari sistemi operativi come Linux, Windows, Mac e BSD.
Scrapy gode anche di una comunità sana e attiva. Ha un numero considerevole di stelle su GitHub (43.100), fork (9.600) e watchers (1.800). Inoltre, ha 5.500 follower su Twitter e 18.000 domande su StackOverflow.
In sintesi, Scrapy è un ottimo strumento per chiunque abbia bisogno di estrarre dati dai siti web in modo rapido, efficiente e estensibile.