
DreamFusionは、テキストから3Dオブジェクトを生成する革新的なAI技術です。この技術は、Google ResearchのBen Poole、UC BerkeleyのAjay Jain、Google ResearchのJonathan T. BarronとBen Mildenhallによって開発されました。彼らは、数十億の画像とテキストのペアで訓練された拡散モデルを基に、3D合成への適用を試みました。
従来の3D合成には、大規模なラベル付き3Dアセットのデータセットと、3Dデータのノイズ除去のための効率的なアーキテクチャが必要でしたが、これらは現時点では存在しません。DreamFusionは、これらの制限を回避するために、事前に訓練された2Dテキストから画像への拡散モデルを使用して、テキストから3D合成を行います。
この技術は、確率密度蒸留に基づく損失を導入し、2D拡散モデルをパラメトリック画像ジェネレーターの最適化のための事前分布として使用することを可能にします。この損失をDeepDreamのような手順で使用し、ランダムに初期化された3Dモデル(Neural Radiance Field、またはNeRF)を勾配降下法で最適化します。これにより、ランダムな角度からの2Dレンダリングが低損失を達成します。
結果として得られる3Dモデルは、任意の角度から表示したり、任意の照明で再照明したり、任意の3D環境に合成したりすることができます。このアプローチは、3Dトレーニングデータを必要とせず、画像拡散モデルに変更を加える必要もありません。これにより、事前に訓練された画像拡散モデルの有効性が実証されています。
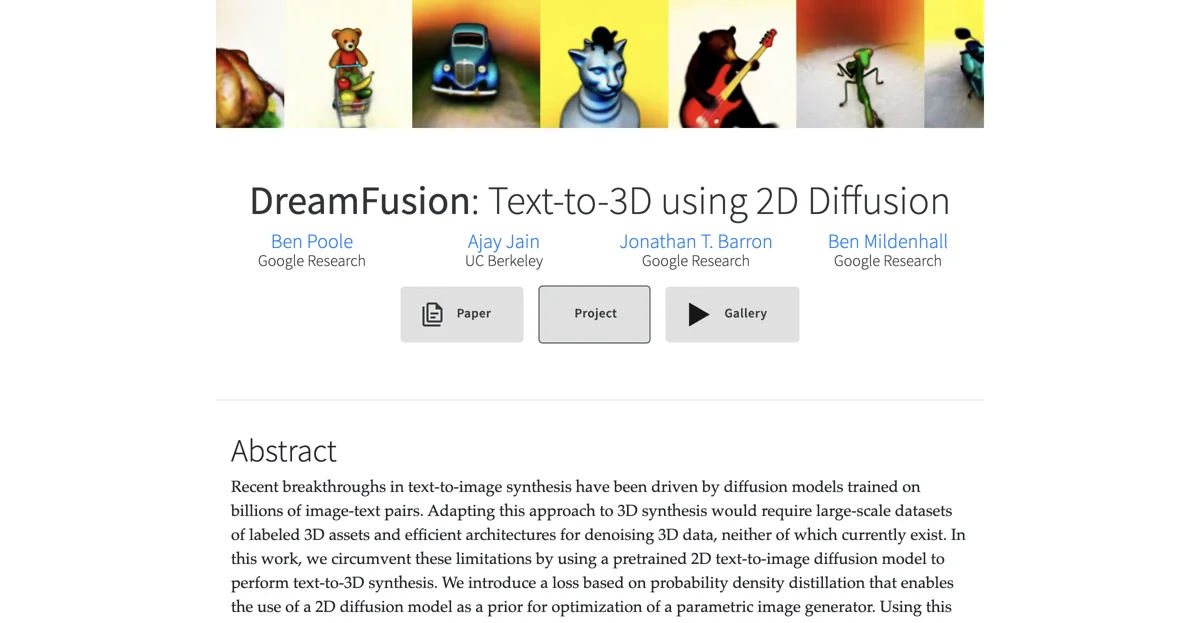
DreamFusionは、キャプションが与えられると、高忠実度の外観、深度、法線を持つ再照明可能な3Dオブジェクトを生成します。オブジェクトはNeural Radiance Fieldとして表現され、Imagenなどの事前に訓練されたテキストから画像への拡散事前分布を活用します。
DreamFusionは、多様なキャプションからオブジェクトやシーンを生成します。完全なギャラリーでは、数百の生成されたアセットを検索することができます。生成されたNeRFモデルは、マーチングキューブアルゴリズムを使用してメッシュにエクスポートでき、3Dレンダラーやモデリングソフトウェアに簡単に統合できます。
DreamFusionは、キャプションが与えられると、Imagenと呼ばれるテキストから画像への生成モデルを使用して3Dシーンを最適化します。Score Distillation Sampling(SDS)を提案し、損失関数を最適化することで拡散モデルからサンプルを生成します。SDSにより、3D空間などの任意のパラメーター空間でサンプルを最適化することが可能です。DreamFusionは、Neural Radiance Fields(NeRFs)に似た3Dシーンパラメーター化を使用して、この微分可能なマッピングを定義します。
SDS単独でも合理的なシーン外観を生成しますが、DreamFusionはジオメトリを改善するための追加の正則化と最適化戦略を追加します。結果として得られる訓練されたNeRFsは、高品質の法線、表面ジオメトリ、深度を持ち、Lambertianシェーディングモデルで再照明可能です。