
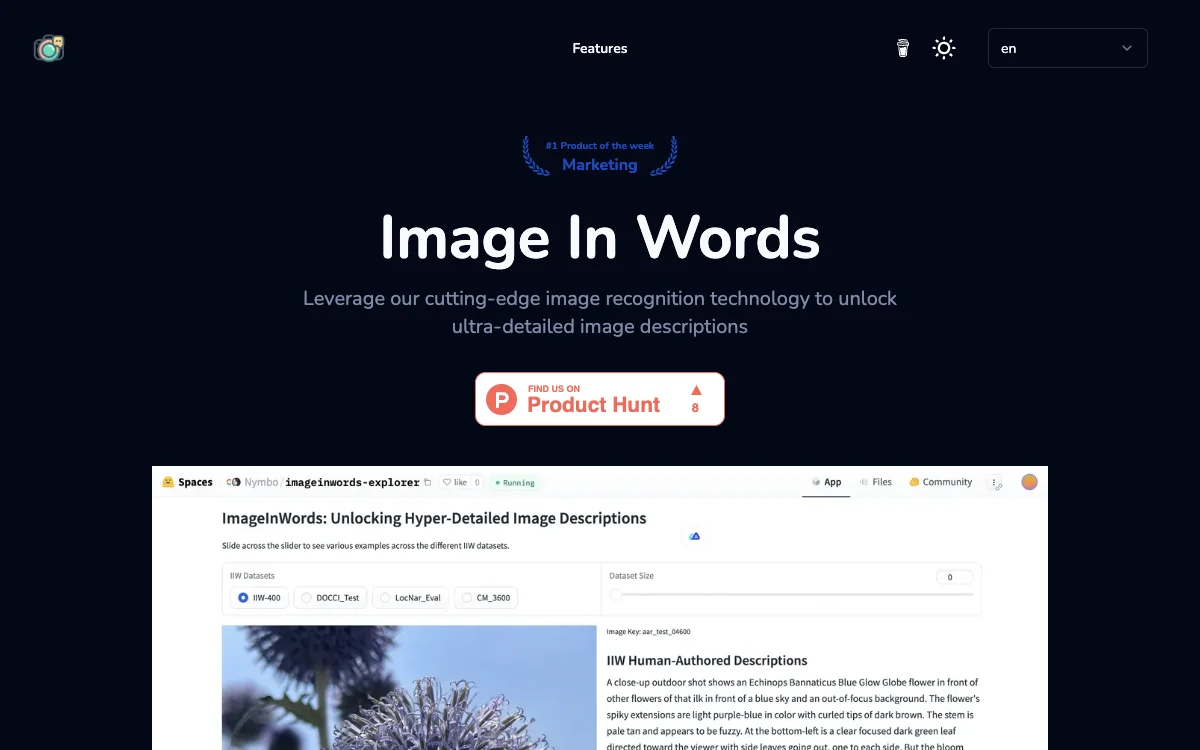
Image In Words는 이미지로부터 초세부 텍스트를 생성하기 위해 설계된 생성 모델입니다. 이 기술은 특히 대형 언어 모델(LLM) 어시스턴트의 인식 작업과 더 복잡한 시나리오에서 AI 인식 및 설명 능력을 활용하는 데 적합합니다. Image In Words는 영어만을 지원하며, 약 100,000시간의 영어 데이터를 사용하여 훈련되었습니다. 다양한 테스트에서 높은 품질과 자연스러움을 입증했습니다.
Image In Words의 주요 기능으로는 인간이 참여한 주석 프레임워크를 활용한 초세부 이미지 설명, 모델 성능의 상당한 개선, 설명에서의 허구적 내용 감소, 가독성과 포괄성, 시각-언어 추론 능력의 강화, 그리고 다양한 응용 분야에서의 우수한 성과 등이 있습니다. 이러한 기능들은 시각 장애 사용자의 접근성 개선, 이미지 검색 기능 강화, 더 정확한 콘텐츠 검토 등 다양한 분야에서의 잠재력을 보여줍니다.
Image In Words는 IIW-Benchmark Eval 데이터셋의 풍부한 버전, 인간이 작성한 IIW 설명(이미지 및 객체 수준 주석), 이전 작업과의 비교(DCI, DOCCI), 그리고 기계 생성 LocNar 및 XM3600 데이터셋을 오픈 소스로 공개했습니다. 이 데이터셋들은 CC-BY-4.0 라이선스 하에 GitHub에서 찾을 수 있으며, Hugging Face에서 'jsonl' 형식으로 다운로드할 수 있습니다.