
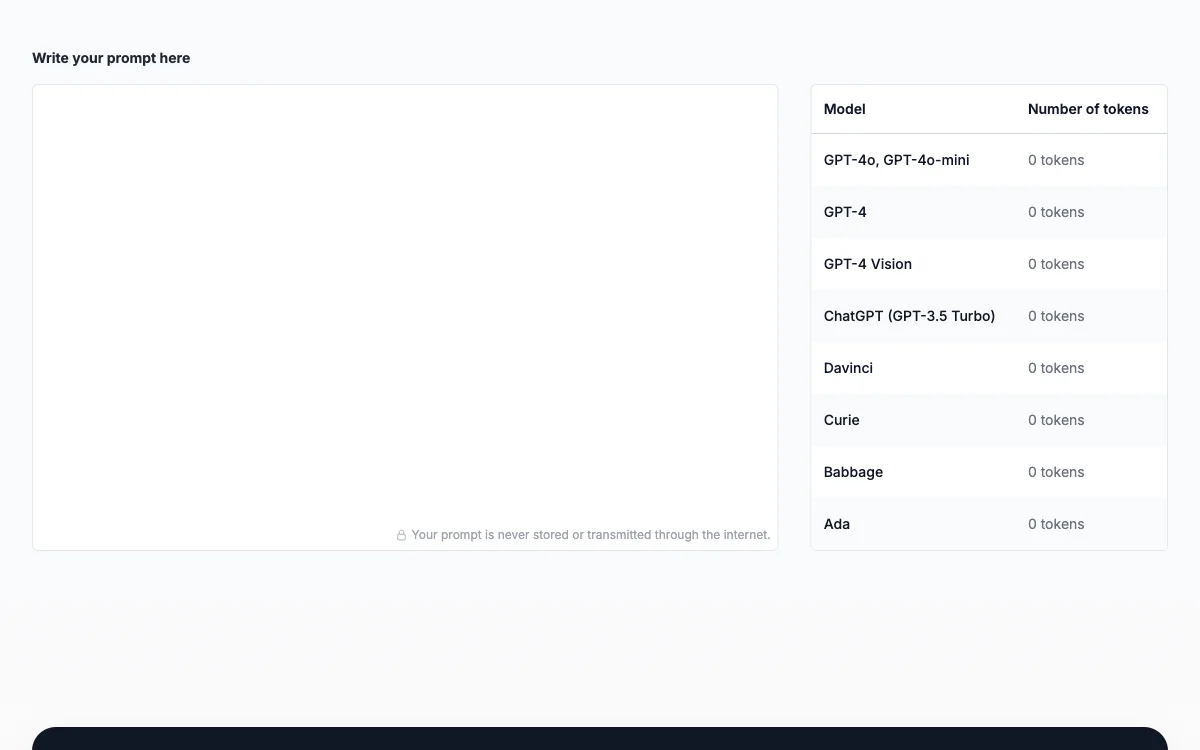
Prompt Token Counter dla modeli OpenAI
W świecie przetwarzania języka naturalnego i pracy z modelami językowymi, takimi jak OpenAI's GPT-3.5, liczenie tokenów jest niezwykle ważne. Token jest najmniejszą jednostką lub składnikiem sekwencji w przetwarzaniu tekstu. Może być to słowo, znak lub nawet podsłowo, w zależności od sposobu segmentacji lub tokenizacji tekstu.
Liczenie tokenów pozwala uniknąć przekroczenia limitów liczby tokenów, które modele mogą przetworzyć w jednej interakcji. Dla przykładu, model GPT-3.5-turbo ma maksymalny limit 4096 tokenów. Świadome zarządzanie liczbą tokenów pomaga kontrolować koszty, ponieważ modele językowe, takie jak GPT-3.5, są rozliczane w oparciu o liczbę użytych tokenów.
Aby liczyć tokeny w promptach, należy poznać limity tokenów dla konkretnego modelu OpenAI, np. dla GPT-3.5-turbo. Następnie należy wstępnie przetworzyć prompt przy użyciu odpowiednich technik, takich jak użycie bibliotek tokenizacyjnych. Po przetworzeniu należy policzyć liczbę tokenów, pamiętając, że obejmuje to nie tylko słowa, ale również interpunkcję, spacje i znaki specjalne.
Ponadto, należy uwzględnić liczbę tokenów w odpowiedzi modelu. Jeśli oczekuje się długiej odpowiedzi, może być konieczne skrócenie lub skorygowanie promptu. Poprzez takie działania można efektywnie zarządzać tokenami i uzyskać jak najlepsze wyniki z interakcji z modelami OpenAI, zapewniając płynne i opłacalne doświadczenie.