
Modelo NLP Mais Eficiente: Pré-treinamento com ELECTRA
Recentes avanços no pré-treinamento de linguagem têm levado a ganhos substanciais no campo do processamento de linguagem natural (NLP), com modelos de ponta como BERT, RoBERTa, XLNet, ALBERT e T5. Embora esses métodos diferem em design, todos compartilham a ideia de aproveitar uma grande quantidade de texto não rotulado para construir um modelo geral de compreensão da linguagem antes de serem ajustados para tarefas específicas de NLP, como análise de sentimentos e perguntas e respostas.
Métodos de Pré-treinamento Existentes
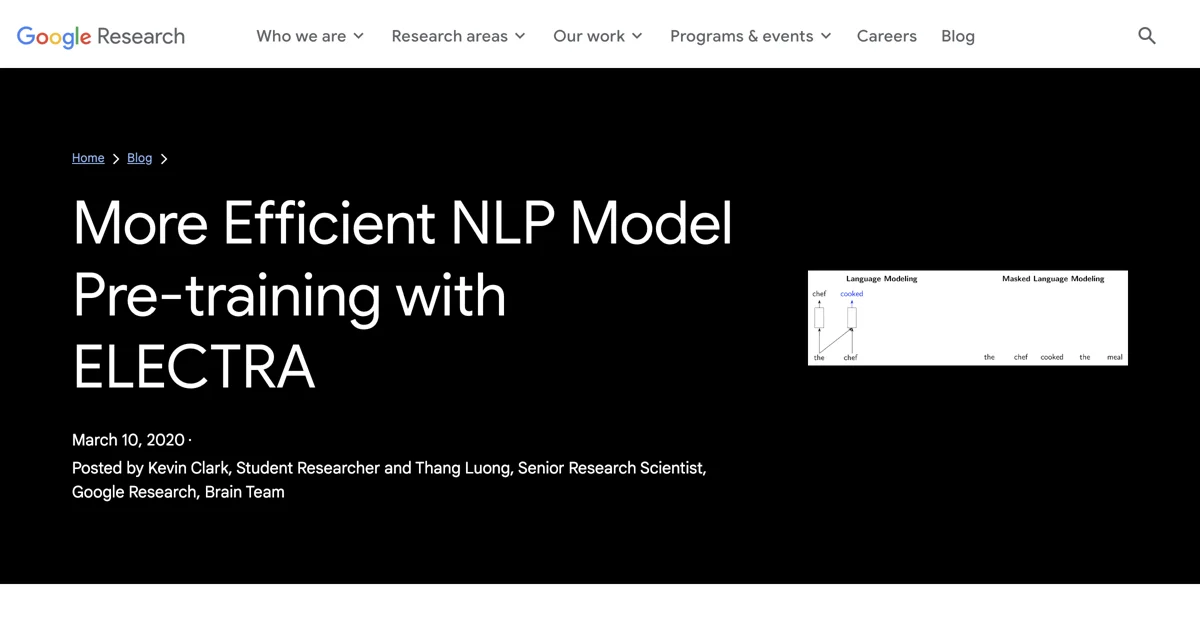
Os métodos de pré-treinamento existentes geralmente se enquadram em duas categorias: modelos de linguagem (LMs), como o GPT, que processam o texto de entrada da esquerda para a direita, prevendo a próxima palavra com base no contexto anterior, e modelos de linguagem mascarados (MLMs), como BERT, RoBERTa e ALBERT, que em vez disso, preveem as identidades de um pequeno número de palavras que foram mascaradas da entrada.
Os MLMs têm a vantagem de serem bidirecionais, pois “veem” o texto tanto à esquerda quanto à direita do token sendo previsto. No entanto, o objetivo do MLM também apresenta desvantagens, pois esses modelos apenas preveem um pequeno subconjunto — os 15% que foram mascarados, reduzindo a quantidade aprendida de cada frase.
A Abordagem do ELECTRA
No artigo "ELECTRA: Pré-treinamento de Codificadores de Texto como Discriminadores em vez de Geradores", adotamos uma abordagem diferente para o pré-treinamento de linguagem que oferece os benefícios do BERT, mas aprende de forma muito mais eficiente. O ELECTRA — Aprendendo Eficientemente um Codificador que Classifica Substituições de Tokens com Precisão — é um novo método de pré-treinamento que supera as técnicas existentes dado o mesmo orçamento de computação.
Por exemplo, o ELECTRA iguala o desempenho do RoBERTa e XLNet no benchmark de compreensão de linguagem natural GLUE, usando menos de ¼ de sua computação e alcança resultados de ponta no benchmark de perguntas e respostas SQuAD.
Eficiência do ELECTRA
A excelente eficiência do ELECTRA significa que ele funciona bem mesmo em pequena escala — pode ser treinado em poucos dias em uma única GPU para obter melhor precisão do que o GPT, um modelo que usa mais de 30 vezes mais computação. O ELECTRA utiliza uma nova tarefa de pré-treinamento, chamada detecção de tokens substituídos (RTD), que treina um modelo bidirecional (como um MLM) enquanto aprende de todas as posições de entrada (como um LM).
Inspirado por redes adversariais generativas (GANs), o ELECTRA treina o modelo para distinguir entre dados de entrada “reais” e “falsos”. Em vez de corromper a entrada substituindo tokens por “[MASK]” como no BERT, nossa abordagem corrompe a entrada substituindo alguns tokens de entrada por falsos incorretos, mas um tanto plausíveis.
Resultados do ELECTRA
Comparando o ELECTRA com outros modelos de NLP de ponta, encontramos que ele melhora substancialmente em relação aos métodos anteriores, dado o mesmo orçamento de computação, apresentando desempenho comparável ao RoBERTa e XLNet enquanto usa menos de 25% da computação. O modelo ELECTRA-Large alcançou uma pontuação de 88.7 no conjunto de testes SQuAD 2.0, superando modelos como ALBERT-xxlarge e XLNet-Large.
Conclusão
Estamos liberando o código para pré-treinamento do ELECTRA e seu ajuste fino em tarefas posteriores, com tarefas atualmente suportadas incluindo classificação de texto, perguntas e respostas e etiquetagem de sequência. Os modelos ELECTRA são atualmente apenas em inglês, mas esperamos lançar modelos que tenham sido pré-treinados em muitos idiomas no futuro.
Experimente o ELECTRA e descubra como ele pode melhorar suas aplicações de NLP!