
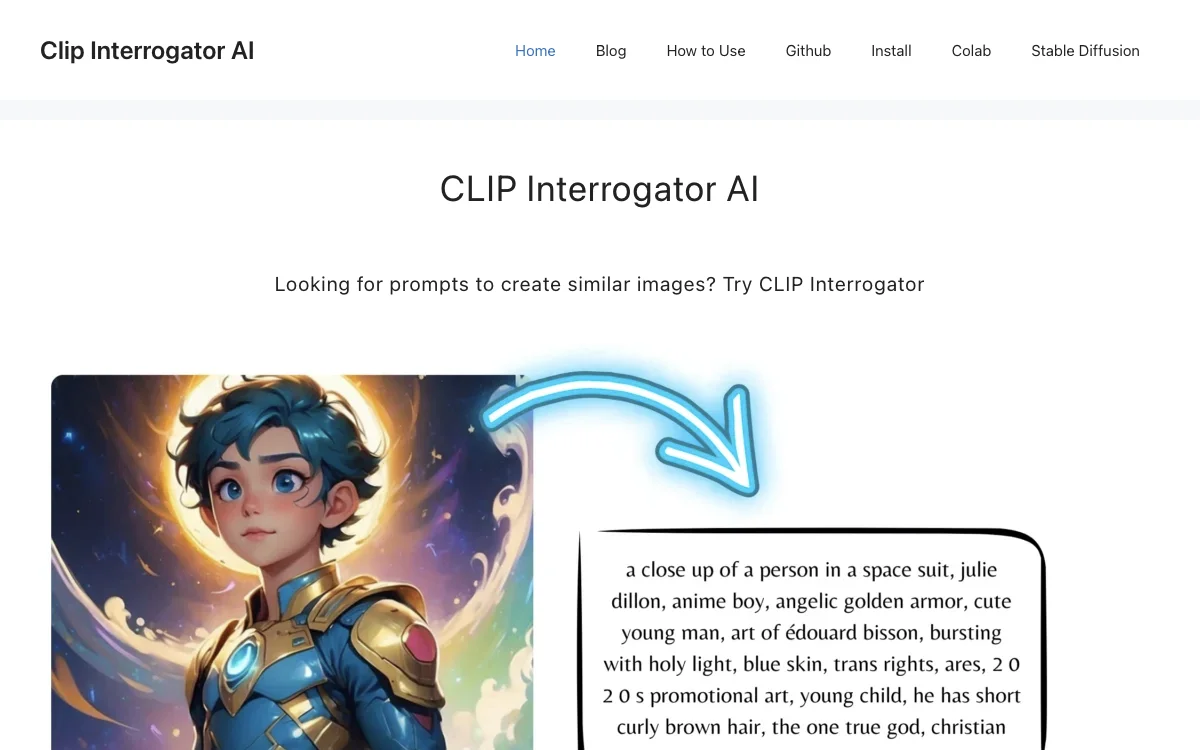
CLIP Interrogator 是一款基于CLIP(对比语言-图像预训练)模型的AI工具,旨在通过分析图像生成描述性文本或标签,从而在视觉内容和语言之间架起桥梁。该工具特别适合那些希望理解或复制现有图像风格和内容的用户,因为它能够识别关键元素并建议创建类似图像的提示。
CLIP Interrogator 的工作流程包括几个关键步骤:首先,使用BLIP模型为图像生成一个基础描述,这提供了图像内容的总体概述。接着,通过添加特定短语(称为“风味”)来增强基础描述,这些短语涵盖了各种类别,如对象、风格和艺术家名称。然后,使用CLIP模型将图像与最合适的“风味”短语进行匹配,确保最终文本更加详细且与图像内容紧密对齐。最后,这些丰富的文本描述特别适用于生成AI图像生成器的提示,提供了对图像元素的更深入理解。
CLIP Interrogator 使用了多种模型,包括BLIP模型、CLIP模型和OpenCLIP模型。BLIP模型专注于生成图像的基础描述,而CLIP模型则通过比较图像与一系列预定义短语来增强描述。OpenCLIP模型保持了原始CLIP模型的核心功能,特别适用于涉及图像与文本描述匹配的任务。
CLIP Interrogator 的研究论文展示了如何通过使用图像描述生成器生成的描述性文本来增强图像分类。研究表明,结合基于图像的分类器和描述性文本分类器可以提高分类准确性。这项研究有助于理解如何有效地利用从图像中提取的语言信息进行图像分类任务。
总的来说,CLIP Interrogator 是一款强大的工具,它通过结合先进的AI模型,为用户提供了一种新的方式来理解和生成图像内容。无论是用于艺术创作、设计灵感还是图像分析,CLIP Interrogator 都展现了其独特的价值和潜力。