
CM3leon是一款由Meta AI推出的先进生成模型,它能够同时处理文本到图像和图像到文本的生成任务。这款模型采用了从纯文本语言模型改编而来的训练方法,包括大规模检索增强预训练阶段和多任务监督微调阶段。CM3leon在文本到图像生成方面达到了业界领先的性能,尽管其训练计算量仅为之前基于Transformer方法的五分之一。
CM3leon的独特之处在于其能够生成基于任意序列的其他图像和文本内容的文本和图像序列。这大大扩展了之前仅限于文本到图像或图像到文本的模型的功能。通过大规模多任务指令调优,CM3leon在图像标题生成、视觉问答、基于文本的编辑和条件图像生成等任务上表现出色。
在零样本MS-COCO图像生成基准测试中,CM3leon取得了4.88的FID(Fréchet Inception Distance)分数,创下了文本到图像生成的新纪录,并超越了谷歌的文本到图像模型Parti。这一成就凸显了检索增强的潜力,并强调了扩展策略对自回归模型性能的影响。
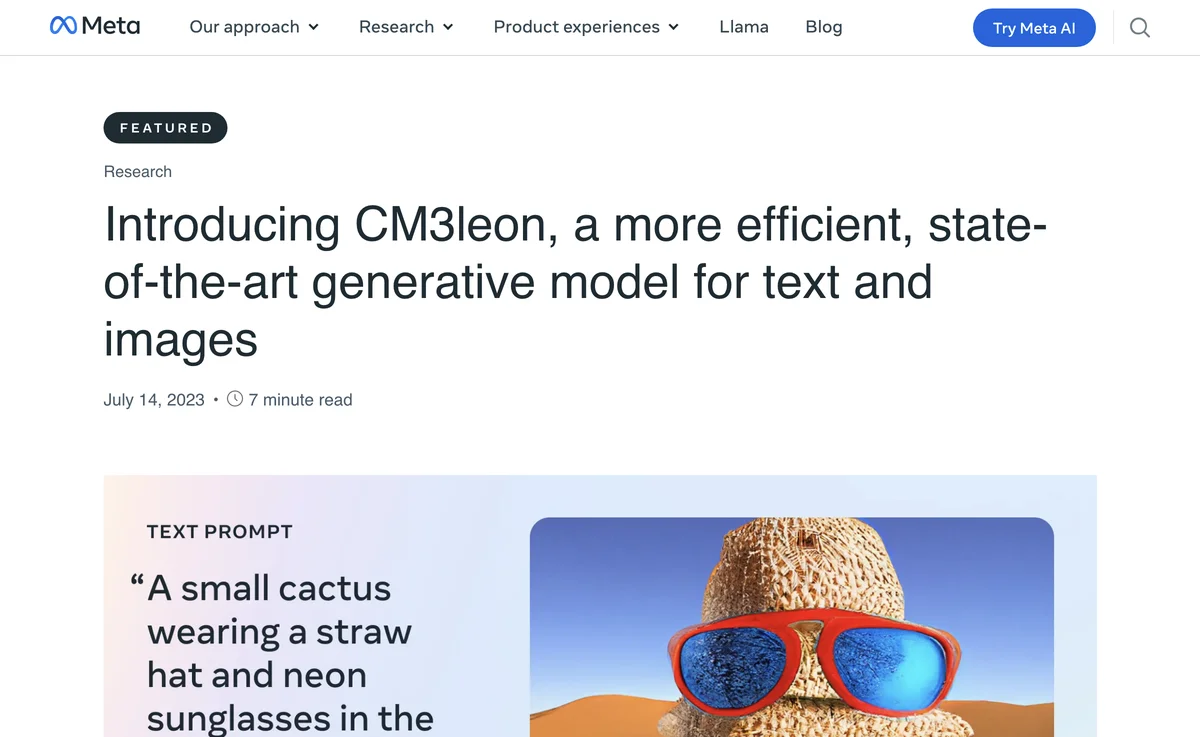
CM3leon还展示了生成复杂组合对象的能力,例如戴着太阳镜和帽子的盆栽仙人掌。在各种视觉语言任务中,包括视觉问答和长文本标题生成,CM3leon都表现出色。即使在仅包含30亿文本标记的数据集上训练,CM3leon的零样本性能也能与在更广泛数据集上训练的更大模型相媲美。
CM3leon的架构使用了类似于成熟文本模型的仅解码器Transformer,但其独特之处在于能够输入和生成文本和图像。这使得CM3leon能够成功处理上述各种任务。随着AI行业的不断发展,像CM3leon这样的生成模型正变得越来越复杂。我们相信,通过共同努力,我们可以创建不仅更准确,而且对每个人都更公平和公正的模型。