
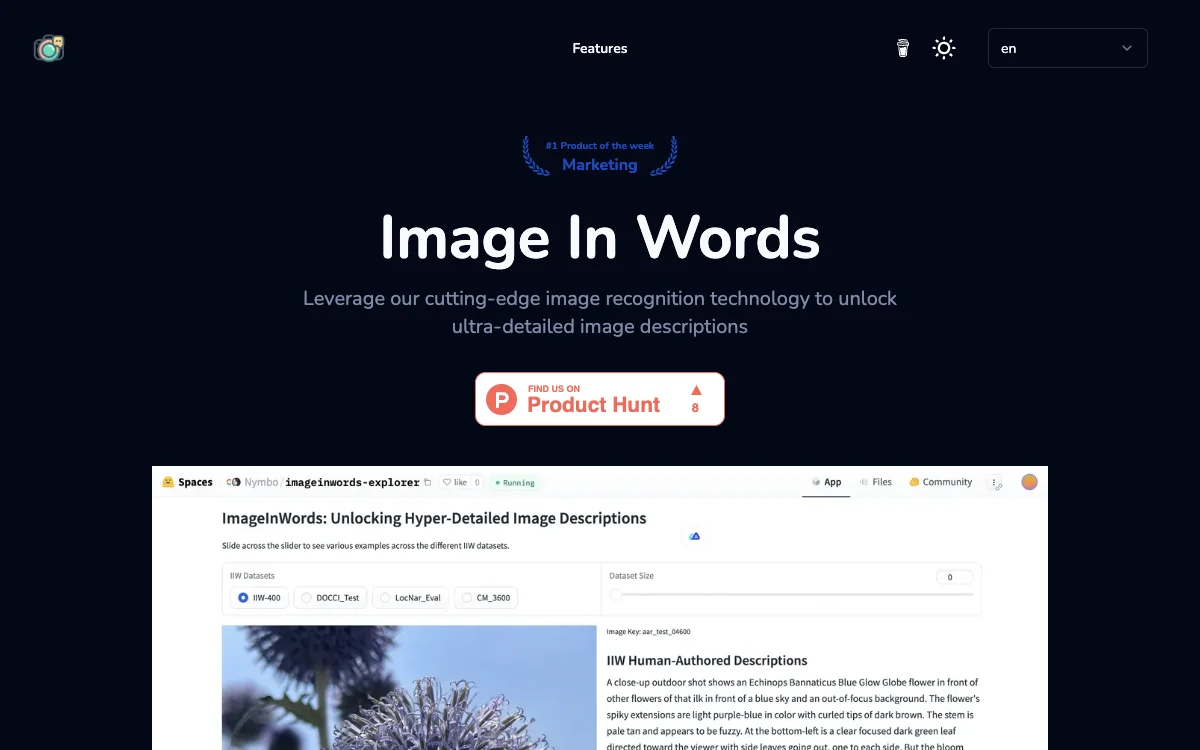
Image In Words 是一款专为需要从图像生成超详细文本的场景设计的生成模型。它特别适用于大型语言模型(LLM)助手的识别任务,以及在更复杂的场景中利用AI识别和描述能力,使用gpt4o。它仅支持英语,并已使用大约100,000小时的英语数据进行训练。在各种测试中,Image In Words 展示了高质量和自然性。
Image In Words 的特点包括:
- 超详细图像描述:利用人类参与的注释框架,确保每个图像描述具有高水平的细节和准确性,避免现有数据集中常见的简短和不相关描述问题。
- 模型性能显著提升:使用IIW数据微调的视觉语言模型在描述准确性和连贯性方面显示出显著提升,模型性能比之前的工作提高了31%。
- 减少虚构内容:通过严格的验证技术,框架减少了描述中的虚构内容,确保描述真实反映图像的细节,而不添加不存在的细节。
- 可读性和全面性:框架生成的描述不仅详细且易于阅读,而且能被广大受众理解,通过捕捉视觉内容的所有相关方面确保全面性。
- 增强的视觉语言推理能力:通过使用用IIW数据训练的模型,视觉语言推理能力显著增强,能够更好地理解和解释视觉内容,生成更准确和有意义的描述。
- 广泛应用:IIW框架在多个实际应用中表现出色,包括提高视障用户的可访问性,增强图像搜索功能,以及更准确的内容审查,展示了其在不同领域的巨大潜力。
我们已发布了IIW-Benchmark Eval数据集的丰富版本,IIW的人类编写描述(图像和对象级注释),与之前工作的比较(DCI, DOCCI),以及机器生成的LocNar和XM3600数据集作为开源。这些数据集在CC-BY-4.0许可下发布,可以在GitHub上找到,并从Hugging Face以'jsonl'格式下载。